
It has been almost a year since my last Editor’s Digest and in that time there have been a few changes within the Central and South Asian studies team. The most significant development is that the editorial responsibilities are now shared between myself and Daniel Wojahn, who joined the DO last year. Daniel has authored pieces on digital humanities and Tibetan studies, with more content forthcoming in the weeks ahead!
This expansion of the editorial team is testament to the growth in both people and projects applying DH tools and methods to Asian studies, and importantly, the increasing diversity within the field. This breadth was evident last year, but has deepened further with the addition of three new contributors—two of whom focus on Central Asia and the other on Partition studies. This digest is the first of two outlining our team’s contributions; Daniel Wojahn will publish the second edition next month.
Soni Wadhwa kicked off the year with a two-part series covering the conference “AI: Future of the Commons: A Conversation on Artificial Intelligence, Indian Languages and Archives,” held in July 2024 at the Maharashtra Knowledge Corporation Ltd (MKCL) in Pune and co-organised with the Centre for Internet and Society, Bengaluru.
In part one, Wadhwa outlined key takeaways on AI applications for Indian languages, noting that while the conference represented progress, future gatherings should seek to allocate more space for under-resourced languages, such as those from Northeastern regions. Like elsewhere, AI has emerged as a major topic of focus across the DO, and its growing presence is evident across our team and beyond, as noted in previous Editor’s Digests by Mariana Zorkina (Sinology editor) and Maria Thomas (Middle Eastern studies editor). This theme will be further explored at the upcoming DO conference on “AI and the Digital Humanities for the Study of Asia, Africa, and Oceania,” where I hope to see strong representation from the fields of Central and South Asian studies.

Languages of India by Vanshhuyaar.
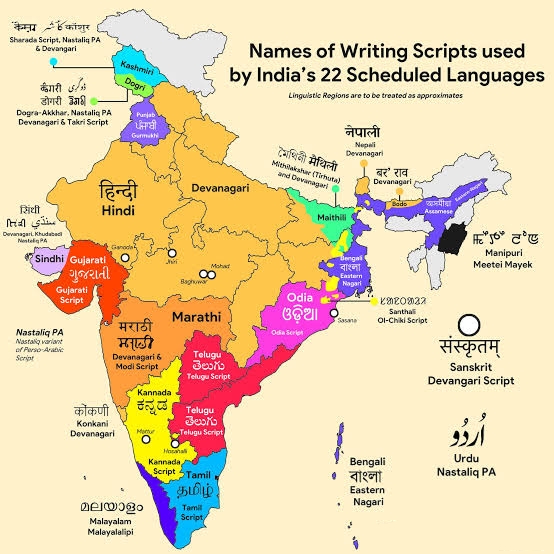{kind=link}
The second part of Wadhwa’s series considered the role of public institutions and digitisation initiatives in India – the second theme of the Future Commons conference. Her biggest takeaway was the role and value of community building, highlighting that successful archives foster community engagement through multilingual interfaces and participatory design approaches like crowdsourcing. A standout example was the People’s Archive of Rural India (PARI), presented in the keynote address by founder Palagummi Sainath, which prioritises linguistic accessibility through human-translated interfaces in 15 Indian languages rather than relying on machine translation.
In her final post of the year, Wadhwa reflected on her own project, the PG Sindhi Library. Revisiting her initial vision outlined in an earlier post, her candid assessment explored how technological developments and restraints, resource limitations, collaborators, and users can all (often unexpectedly) shape digital archives.

Erica Biagetti contributed a series demonstrating how WordNets and Treebanks can be used together to study formulaic diction in Sanskrit texts. Her first post serves as a necessary introduction to the use of formulaic composition in oral poetry, particularly Rigvedic formulas, and contemporary linguistic approaches for their study. Building on this, part two offered a practical demonstration that walks readers through a novel approach for extracting formulas from Sanskrit texts, using the KILL THE DRAGON formula from the Rigveda (RV) as an example. Biagetti’s next piece will be out next month, so stay tuned!

Syntactic tree of RV 1.130.4a-c
Moving away from his popular series on training OCR/HTR models, Rohan Chauhan introduced Aksharamukha, a versatile transliteration tool supporting conversion between an impressive 121 scripts and 21 romanisation methods. Beyond basic transliteration, the tool incorporates OCR functionality for text extraction from images, though results vary depending on script support and image quality. Nevertheless, the open-source nature of the tool and its user-friendly interface make it suitable for a variety of users. As Chauhan notes, it is “a useful addition to the digital toolkit” for those working with South and Southeast Asian scripts.

We welcomed Gursimran Kaur Butalia as a guest contributor, whose debut post probed various tools and techniques, such as geospatial information systems (GIS) and OCR, and their potential for enriching Partition studies. This complements a piece written by Roshane Shahbaz last April, “Partition Chronicles: Navigating Punjab’s Historical Repositories,” collectively demonstrating how digital methodologies can enhance our understanding of displacement and resettlement narratives.

Looking ahead, there will be a piece by Aizat Ishembieva, who will be writing on the digitisation of materials collected from the Danish Pamir Expeditions to Central Asia in the late 19th century—further expanding our coverage of Central Asian digital humanities initiatives!
The integration of AI appears to not only be shifting research practices but also stimulating important discourse around potential benefits, limitations, and ethical/legal considerations. While this trend mirrors developments across digital humanities more broadly, our team’s contributions highlight region-specific applications and challenges, and I anticipate this trend will continue in future posts. I look forward to seeing more from our contributors and to the ongoing use of DH in our fields. If you or someone you know is interested in submitting a piece to the DO, please visit our submissions page.