
Poetry is among the best kind of texts to be manipulated with a programming language. Most of that work lies in defining clearly what result you wish to get, and preparing the raw data, about which I want to share my experience here.
In its contents, poetry is of course among the most ‘human’ ways of using language. With its poetic license of bending grammar rules, excessive use of symbolism and figures of speech, and intentional multiple connotations, its meaning is virtually impenetrable for a computer. However, in its formal structure, poetry is often highly regular, which can easily be captured by instructions given to a computer. Additionally, if a large corpus of poetry is involved, vocabulary structure can also be tracked, and probably better so than a human could do on their own.
In this example, both aspects will be made use of. The example which I discuss here is based on the Psalter from the Bible, specifically its Latin text (the so-called Vulgate), but its application to other corpora, in different languages, should be obvious. In fact, because I have tried my best to implement a modular approach, the code I came up with can be applied to a different use case with only very few changes.
The work before the work
A lot of effort goes into making absolutely clear before hand what the task is that the computer needs to execute. Here is the description I came up with:
Given a corpus of words that are assumed to be known, extract all Psalm verses that are made up of only those words.
The idea behind is that people who go to Church often, will in fact already know a fair amount of Latin vocabulary without any formal studies. For example, most Catholics will be able to sing the Our Father in Latin and will be able to decipher the meaning of the Creed in Latin, and so forth. Most of this passive knowledge of Latin is contextual, meaning, they would only know the meaning of a Latin word when seen in the context of e.g. the Pater Noster, (did you guess yourself that that means Our Father?). Some of that knowledge is also based on cognates; words in Latin that look (almost) the same in English. Now, if we want to come up with a method to start reading the Bible in Latin, it stands to reason to start with the Psalter, which is one of the most used parts of the Bible. It further stands to reason to start pointing out little snippets of the Bible that somebody could decipher with only very little help. Psalm verses consisting of known words, be it in a word order and context different from how the person knows it, would be an excellent starting point. And so, the task is then to find all those verses. This, clearly, is a task that cannot be done well by hand, by a human being. Much better will it be, to have a computer go through the corpus.
It will be good to have a flexible solution, one in which we can easily change the word list and even change the text through which one searches. For example, what if we want to tailor to the needs of people who have a broader and more regular exposure to Catholic liturgy, and who will therefore know the meaning of much more Latin texts? What if we want to branch out from the Psalter to other parts of the Bible, e.g. the Gospels?
Therefore, we want to store the word list and the corpus separately. We want to load them in, and then perform searches on them, spitting out results in a meaningful fashion. What that fashion is, is something we might be able to conceive of already know, but we might also come to think of it only later during the process of writing the code and testing it.
Our first task, then, is to come up with the word list and corpus.
The process of drawing up the word list I won’t discuss here, but let it be given as a text file with one word on each line. In our case it consists of just short of 700 words.
We do not have to type out the entire Psalter, but instead we will take it from the internet. I took it from here: http://www.sacredbible.org/studybible/OT-21_Psalms.htm
I copied the entire text and pasted it in Sublime Text, a program often used to write code in but also very useful to clean up text data. In our case, there definitely is cleaning up to do. We need to ask ourselves, what do we want? As you can see, the text now has at the top and bottom links; they can be deleted immediately, we do not need them. The main text consists of Psalm headings, a Latin verse, an English translation, and sometimes a comment. We only want the Latin verse. Using Sublime Text‘s ability to search using ‘regular expressions’ (search for “regex” for more information) We can fish out all the rubbish and delete it.
For example, searching for “~ .*\n” will find all comments.

Searching for “\{.*\n will find all Psalm headings.

Similarly, empty lines can be deleted. What is left is a new Psalm verse on every two lines, Latin first, then English. Searching on the internet for how to delete every second line in Sublime Text yields a simple method of searching for “.*\n.*\n” and hitting Find All, after which multiple cursors will blink which can be moved from line to line to select all even (or all odd) lines.
The result is two files looking something like:

As you can see, I also deleted the { and } from the Psalter text. I could have deleted the verse numbering altogether but I figured it would be useful to keep it. This does mean, however, that we will have to write more complicated code to have the computer divide the line in a verse number part and a text part.
Note that I also flattened the text, by which I mean that I made everything lower case, deleted all punctuation, and replaced “æ” by “ae”. This is to make it easier for the computer to not overlook anything.
Also note that I use white text on a grey background because I find it easier on the eyes. I set up this color scheme in whatever program I use for coding. Its merely a settings thing and not a necessity.
Onto the code!
The work
I prepared the data on the notion that Python can read a text file line by line, easing the process of working on the data verse by verse. After first experiments, I quickly realised Python could not read the file straight away, but needed a little extra help to read it as UTF-8.
The first few lines then became:
# (C) L.W. Cornelis van Lit 2017. The Digital Orientalist. # Dependencies import codecs # Importing Psalter psalterNumberAndText = list() with codecs.open("psalterreduced.txt", encoding="utf-8", mode="r") as ps: psalter = ps.readlines() for verse in psalter: verseNumberAndText = verse.strip().split(";") psalterNumberAndText.append(verseNumberAndText) # Importing Word List with codecs.open("latinvocab.txt", encoding="utf-8", mode="r") as wl: wordList = wl.read().splitlines() wordSet = set(wordList)
This code loads the poetry and the word list into memory. The strip command deletes any new line markers. The split command creates a list of two items, the first (in Python assigned the number zero) is the verse number, the second the text. This command is run over every line, and every pair of number/text is then put together in a list called psalterNumberAndText.
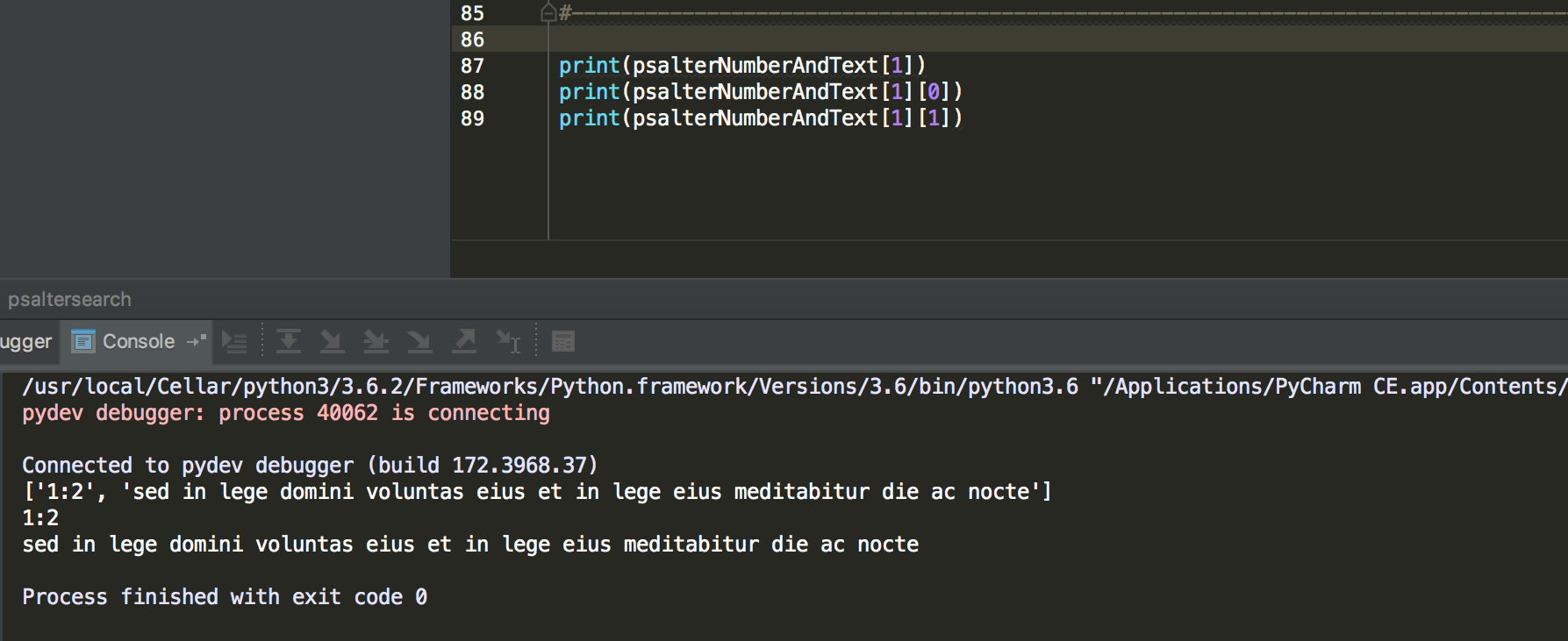
To illustrate, we can run a simple print command to have Python print out the content of something in the Console. If we print out psalterNumberAndText[1] we want to see the entire content of the second item of the psalterNumberAndText list, which is itself a list of two items, a verse number (1:2) and a text (sed in lege…). If we give the additional instruction to only print the first item (by adding [0]), we only get the verse number, and similarly for the text.
As a warming up exercise, we can check the length of a Psalm verse.
## Length of psalm verse
def lengthOfVerse(psNumber):
print("{0} is the length of Psalm {1}, which reads {2}".format(len(psalterNumberAndText[psNumber][1]), psalterNumberAndText[psNumber][0], psalterNumberAndText[psNumber][1]))
#Example:
#lengthOfVerse(23)
If we run it, with the hash removed on the last line, we get:
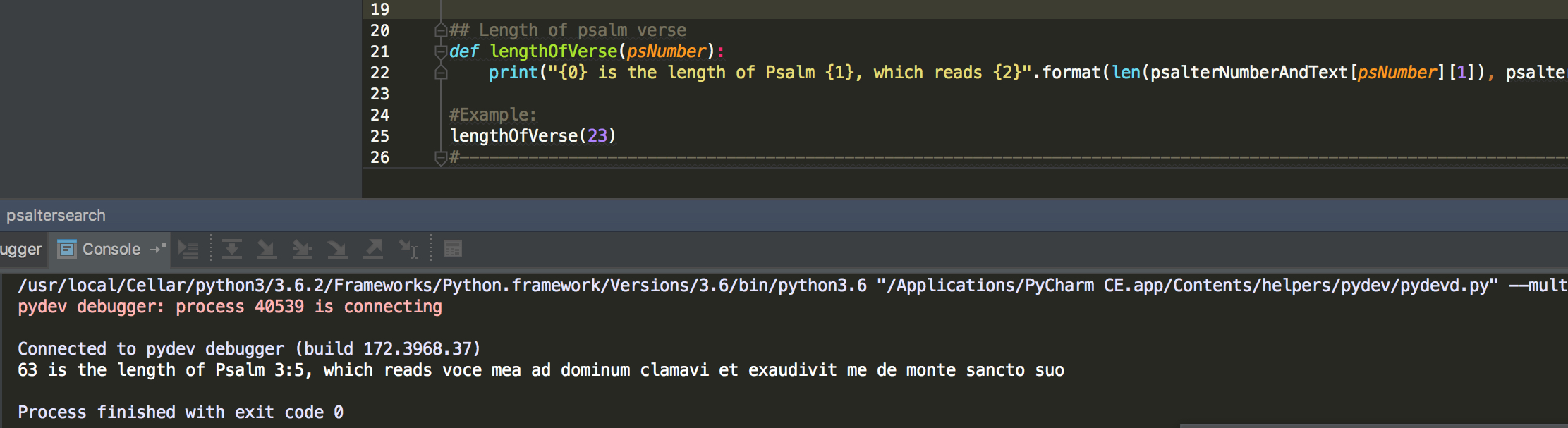
Note that we wrote this code inside a function, to make it more modular and easier to change without breaking all of our code. The example of the length of a psalm verse can be the beginning of an advanced selection procedure based on length. However, for us, we will take our search function in a different direction, by making use of the word list. I will describe this in a next post. Stay tuned.
One thought on “Tackling Poetry with Python”