
So you have heard about some cool text analysis tools that identify word frequencies, generate word clouds, and look for trends and patterns? Can’t wait to try them out? Well, after uploading your favourite Chinese text it is certainly frustrating to find out that the term with the highest frequency in your corpus turns out to be a comma. Would this be a problem if you analyze something written in English? Sometimes it is and sometimes it isn’t, depending on the feature of the specific tool. But for tools that automatically filter punctuation, usually they cannot identify non-English punctuation.
This is a typical problem for scholars who work with Chinese materials – text analysis tools or some functions of the tools are not applicable to their text. Accordingly, a preprocessing step is required to transform Chinese-based text to computer-friendly data prior to analysis. One way to achieve this is via OpenRefine, a powerful tool that is excellent for shaping natural language to structured data and cleaning messy data. In this series of three posts, I will share some ideas about data cleaning Chinese text with OpenRefine.

A sample of a word cloud generated by Voyant that indicates a punctuation mark to be the term with the highest frequency (15083 occurrence).
Starting a Project with OpenRefine
Formerly developed by Google and named Google Refine, OpenRefine is a free, open source piece of software. It can be downloaded from its official website or GitHub. After installing the software successfully, you will see that it runs in your browser. Please note that OpenRefine operates on your local computer, and it does not upload your data anywhere. The to-be-refined data can be imported from a variety of sources, for example, a file on your local computer, URLs, or text pasted to the OpenRefine clipboard.
In this post, I will remove punctuation of Qīngshǐ gǎo・Liènǚ zhuàn 清史稿・列女傳 from the online library Chinese Text Project. To replicate my demonstration, you can obtain the original text by searching “清史稿” on the Chinese Text Project main page or by clicking this link, and either way should direct you to the digitized book. Liènǚ zhuàn 列女傳, is a section of the book, comprising of four chapters starting with Lièzhuàn èrbǎi jiǔshíwǔ 列傳二百九十五 and ending at Lièzhuàn èrbǎi jiǔshíbā 列傳二百九十八. While you may directly use the URLs of the four chapters to import data to OpenRefine, the Chinese Text Project offers the possibility to download the plain text versions, which is more friendly for computers to read. To do this, register an account for the Chinese Text Project. Once you sign in the “plain text” option will be shown at the top-right corner of each chapter. The plain text versions of the four chapters can be copied and pasted to the clipboard on the main page of OpenRefine, or can be organized into a text file before being uploaded to OpenRefine. Either way should usher you to the preview page of your project.
The preview page offers many options to organize the data even before the start of your project. For our project (natural laguage), it works best as a line-based text file, which is the default on OpenRefine. We only need one alteration for the pre-setting – unchecking the “store blank rows” box to discard all the blank rows from the original text. Next, on the top-right corner, name this project “清史稿列女傳,” and then click the “create project” button. After processing, the project 清史稿列女傳 is created. At this point, only the first ten rows of the text are visible. But you may choose to display more rows or to go to the next page to view more data. Now, the project is ready for its first task – punctuation removal.
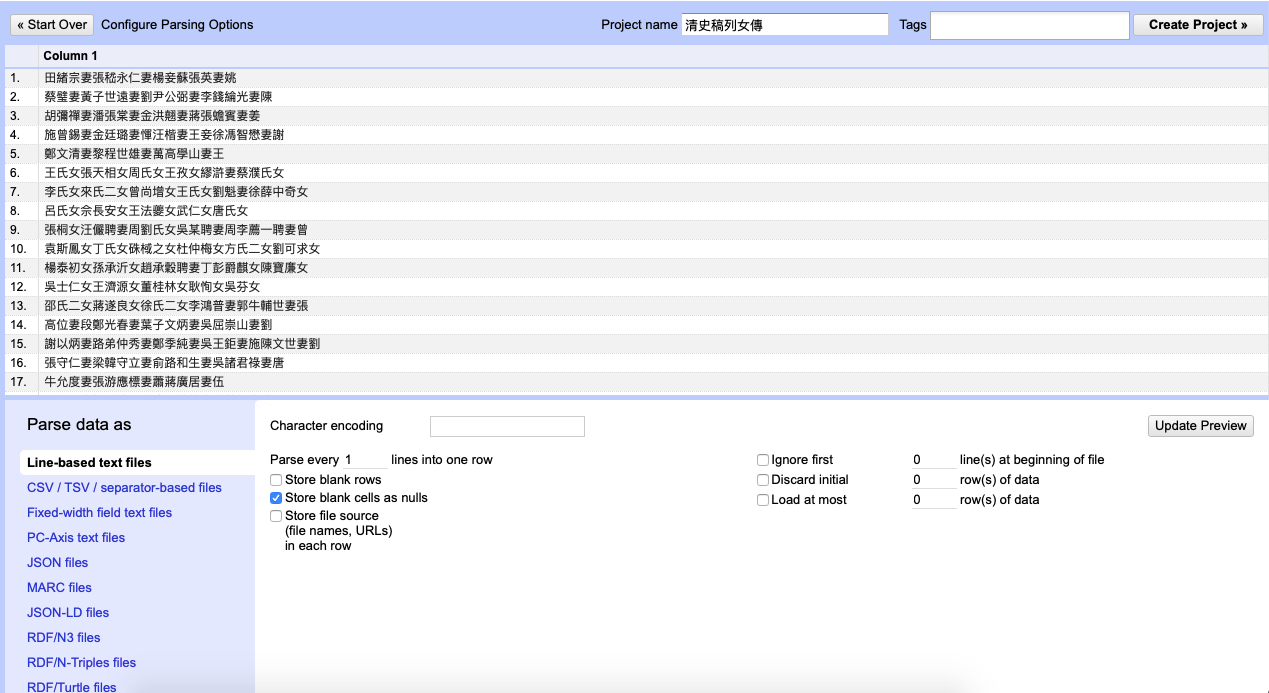
The preview page of the project 清史稿列女傳.
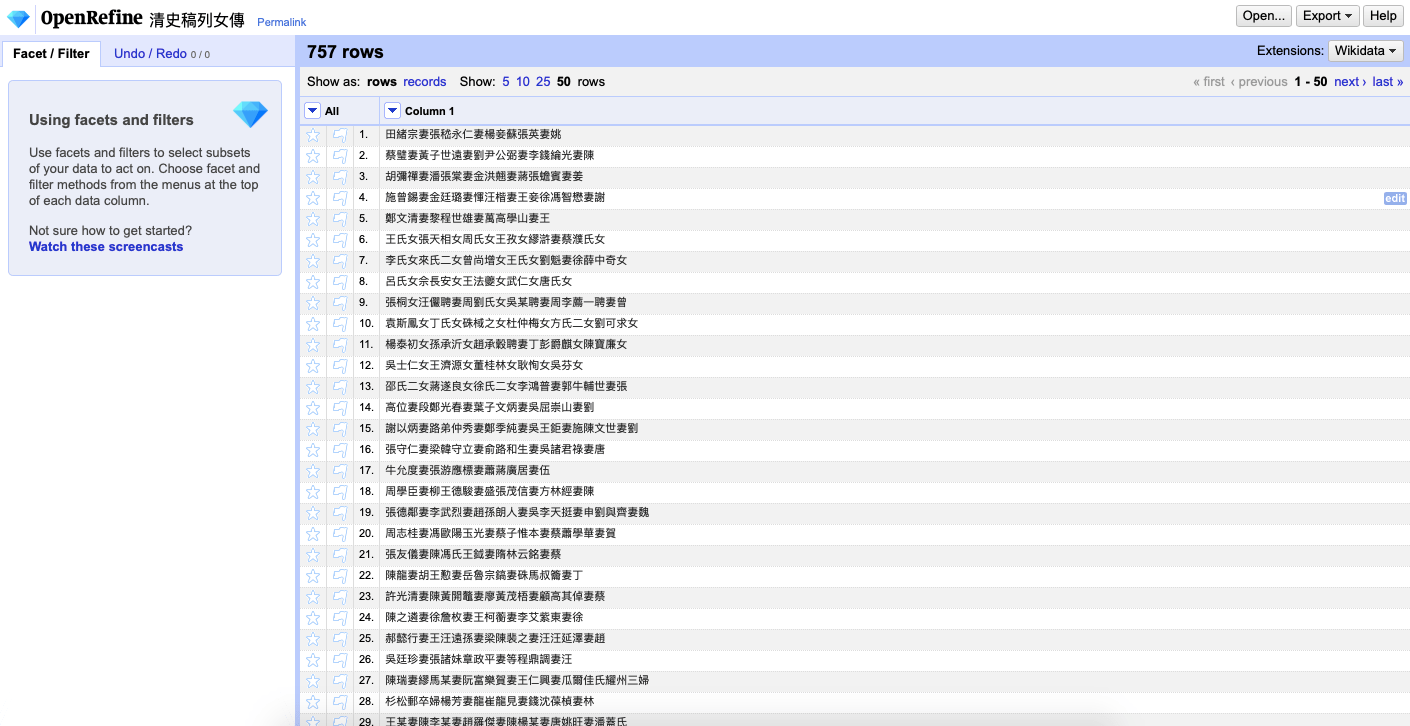
The created project 清史稿列女傳 displaying 50 rows per page.
Removing Punctuation
The drop-down menu on the left side of “Column 1” contains a number of editing options. We need to go to “Edit Cells”, and then choose “Transform…”. In the “Expression” box in the pop-up window, type value.replace(“,”,””), which immediately generates the preview of the altered text. Click the “OK” button to apply this action to your project and all commas will disappear. The above noted expression replaces the commas in the text with blank space for all the cells in Column 1. Please also note that it is important to switch the input setting of your computer to Chinese mode when typing the comma (,) to make the magic work.
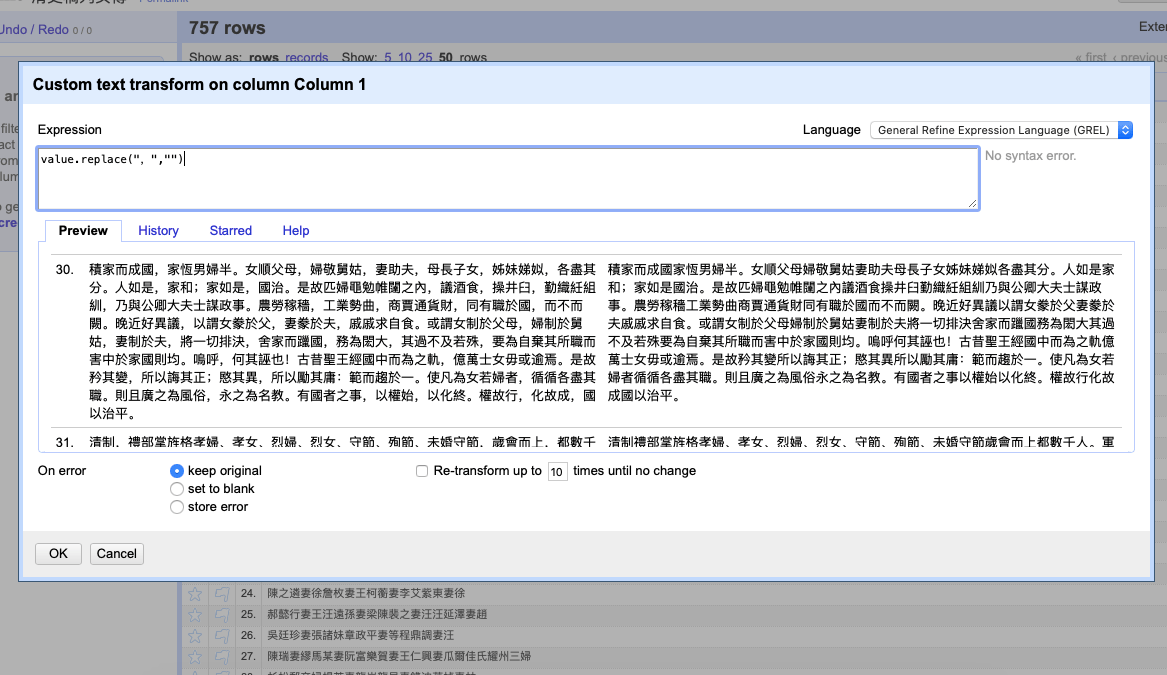
The expression to eliminate commas.
We can continue to remove other punctuation – or any other unwanted data – by applying similar expressions to the project. For examples, the expressions to remove periods and question marks are value.replace(“。”,””) and value.replace(“?”,””) respectively. In this project, we need thirteen expressions to eliminate all the punctuation marks in the project, which are ,。、;:「」『』!?《》.
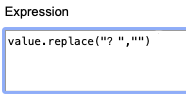
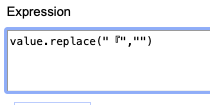
Sample expressions.

Clean text without punctuation marks.
Punctuation removal can also be achieved by advanced techniques such as coding in Python or R, or via straightforward methods, for example, the “Replace” function in Microsoft Word. Compared to these methods, using OpenRefine is easy for digital humanities’ novices and offers an array of management options. By clicking the “Undo/Redo” tab, you will see a list of actions recorded for your project. Moving up and down the list enable you to undo or redo certain actions. The chosen actions can also be extracted as a JSON (a file format that stores data) file, which you can then apply to other documents which require the same sort of processing.
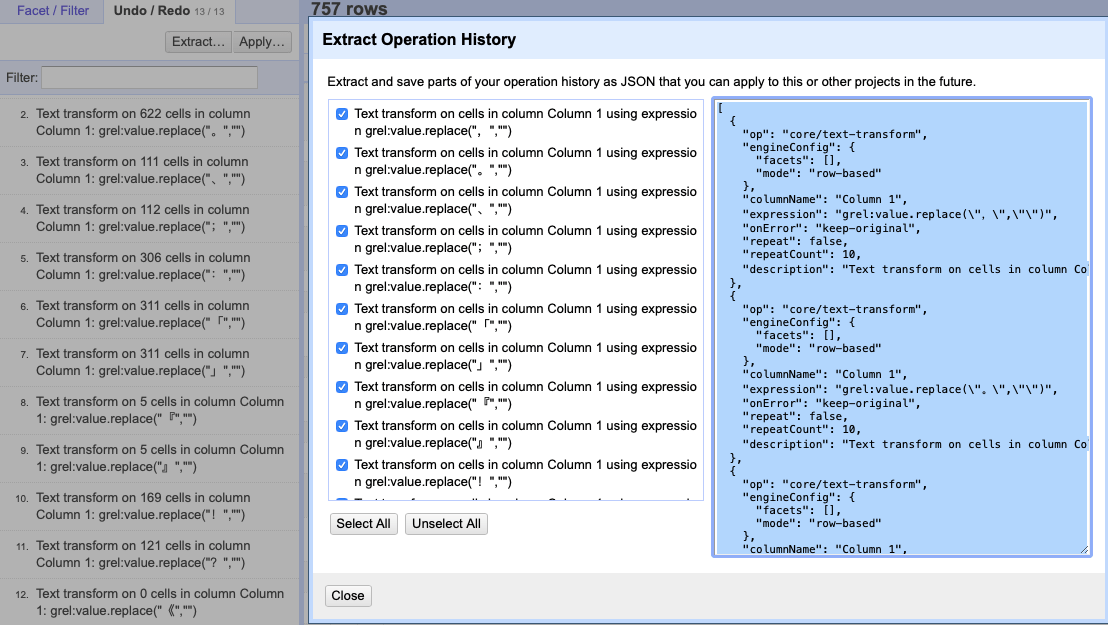
The undo/redo clip (left) and the extracting operation history window (right).
In this post, I have explained how to import data into OpenRefine and how to write expressions to remove punctuation in Chinese text. This is the first step to making a text more readable for text analysis tools. Other than cleaning text, OpenRefine helps to change natural Chinese text to structured data for more advanced data analysis tasks. In my next two contributions to the Digital Orientalist, we will discover some of the applications of OpenRefine when shaping Chinese text for different text analysis results. Don’t forget to come back and check them out too!
Thank you so much! I was confused about the annoying “,” in my corpus until I read this article! 我正在做一个美术馆的评论分析, 感谢您的文章!