
Every humanities researcher dreams of finding keywords in archival documents quickly and easily. Thanks to OCR technology, we have realized this dream for Latin letters. With Ctrl + F (or cmd + F) research, we can easily locate our keywords among thousands of words, sentences, and pages. This is not always so easy for historical documents. Today, thanks to machine learning and artificial intelligence technology, OCR can work successfully for some archival documents. This article introduces two important search engines and databases designed for printed archives in Ottoman Turkish: Wikilala and Muteferriqa. These two projects, which are being excitedly received by researchers in Ottoman studies, allow for the navigation of the pages and lines of thousands of printed archival documents on the basis of single words.
Wikilala, which is beginning to be referred to as the ‘Google’ of Ottoman Turkish printed archives, offers researchers the opportunity to conduct thematic research easily thanks to its digital database containing Ottoman Turkish books, magazines, newspapers, and other types of documents. Project manager Sadi Özgür and project consultant Dr. Harun Tuncer completed and launched Wikilala in early 2021. Researchers have the opportunity to search by entering both Latin and Arabic letters or phrases.
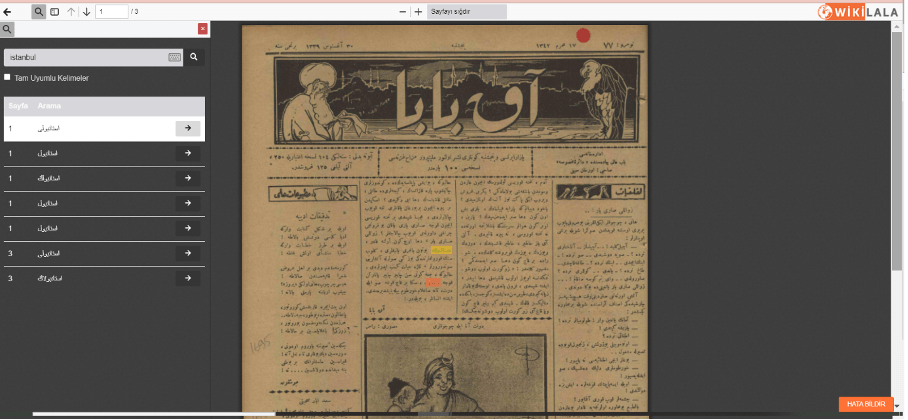
Beta version of the Wikilala database containing 109,321 different documents, including 4,658 books, 45,470 newspapers, 32,450 magazines, and 26,743 articles published in Ottoman Turkish.
Another great initiative is the Ottoman Turkish search engine is Muteferriqa. The project, managed by Kürşat Aker and Ozan Ceyhan, offers a vital search engine service with artificial intelligence technology and machine learning techniques. Thanks to the project, it is now possible to search the full text of Ottoman Turkish books, magazines, newspapers, and all kinds of printed archival material. Muteferriqa also offers digital resource management services for researchers and institutions. Thus, you can manage all digitized printed archives such as maps, postcards, manuscripts, pictures, and photographs in one place.
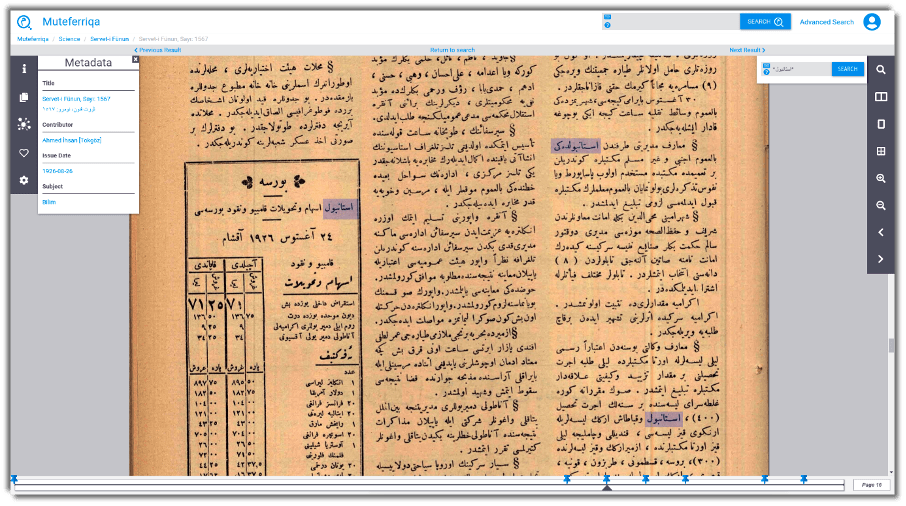
Thanks to Muteferriqa, which supports all the basic features expected from search engines as an infrastructure, historians, linguists, and researchers from all other fields can search Ottoman texts for systematic and multi-layered research in minutes.
These two initiatives, which provide essential convenience for Ottoman researchers working in the difficulties of pandemic, are precious technological contributions to the intellectual knowledge production. Using OCR technology for Ottoman Turkish, which still needs improving in the case of Ottoman manuscripts and is only working for printed works at the moment, is a significant advancement upon which to base future developments.
One thought on “Innovative Designs on Ottoman Turkish Search Engines: Wikilala and Muteferriqa”