
This is a guest post by Adam H. Lisbon. Many thanks to James Morris for coordinating it.
In August of 2022, the OCLC’s WorldCat.org website updated its interface, resulting in no Romanization for Chinese, Japanese, and Korean (CJK) titles or publishers. Romanization was restored in October of 2022, and this time frame offers a moment to reflect on why we need Romanization of CJK and other non-Roman script orthographies, especially in the context of databases and other discovery tools that help locate scholarly and popular sources.
I am a librarian who builds collections in Japanese and Korean, and I had never considered how essential Romanized bibliographic data was until it was gone. I speak Japanese, but not Korean. In either language Romanization is an essential tool for quickly confirming the pronunciation of names and obscure vocabulary. When WorldCat.org’s new interface released I immediately emailed OCLC with concrete examples of why the loss of Romanization was problematic:
- In Japanese, pronunciation of characters/kanji can be obtuse, especially regarding names.
- A common name like “Akira” has dozens of possible kanji.
- A common kanji like 明 has at least 13 pronunciations in names, including “Akira.”
- Place names have the same pronunciation challenges:
- 十三, pronounced jūsan, means 13.
- 十三, pronounced jūsō, is a neighborhood in the city of Osaka
- Creative license taken by authors: 鬼滅の刃 / Kimetsu no Yaiba is a popular manga/anime. The word 鬼滅/kimestu is made up. It will not appear in any dictionary. How it is pronounced is a mystery even to native Japanese speakers without confirmation.
I sent a more detailed email to OCLC explaining these issues, and shared it with the greater East Asian Studies librarian community on the Council of East Asian Libraries’ Google Group. There was a consensus that many of us, including native Japanese speakers, regularly rely on romanization to confirm correct pronunciations. My examples above are specific to Japanese. Examples from Chinese and Korean Studies where romanization is beneficial would be very welcome in the comments section at the end of the article.
Romanization is also about access. Students beginning their CJK language studies rely on it. Graduate students starting to dive into the classical forms of these languages also benefit as they are exposed to conventions and norms they will not have learned about while studying the modern form. Many of us have opted to type Romanization into a search engine, database, or library catalog because it would still bring up the same result, or because we didn’t know which variation of a character would be used (島 vs. 嶋, or use “shima” so that both will come up in search results), or because we had to use a computer that did not have foreign language input methods installed. Perhaps there are people who didn’t even realize that opting for Romanization may have such benefits.
In the context of Libraries and the daily work of building collections, Romanization is important for those who don’t have any ability to read non-Roman scripts. While I read Japanese, my colleagues in acquisitions do not. Romanization smooths communication and reduces errors. In 2019, I did an IRB approved survey regarding language fluency of Librarians who do selection and/or work in acquisitions units. Participants self-assessed their language ability for the languages they collected in or worked with.
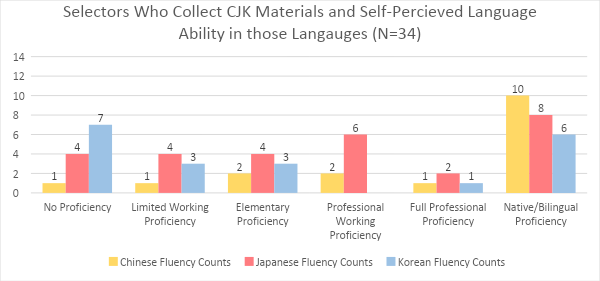
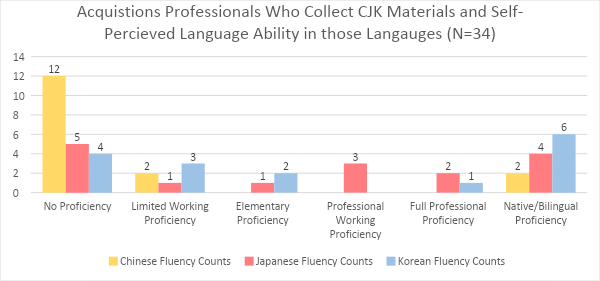
From this small sample of 34 we can see there are library professionals helping build CJK collections with little or no CJK language proficiency. There is no library budget big enough to hire selectors, acquisitions specialists, and catalogers for every language in a library’s collection. It is possible to move through the workflow of selecting, ordering & purchasing, receiving, cataloging, labeling, and shelving, and circulating CJK books without any romanization readily available, but the process would be much more error prone and time consuming.
OCLC’s oversight is unfortunate in that it implies CJK/Non-Latin script records were never considered or examined when testing the new interface, or the issue was known but not considered something that needed to be addressed before it was rolled out to the public.
This happens in other technological spaces, where software used across national borders and languages is developed from a monolingual English-centric perspective: To program macros in Excel with VBA, non-Latin glyphs cannot be used in the code. It is especially problematic if the macro will write out, find, or find and replace a text string with CJK scripts, etc. In the realm of citation management software, there is no mainstream product that acknowledges citing a CJK in English requires parallel data fields for both the native script and a Romanization of that script. The only exception would be Frank Bennett’s Juris-M, a special off-shoot version of Zotero. Zotero itself has shown no interest in integrating such a feature. I explored how this impacts the use of adopting such software in a paper titled “Multilingual Scholarship: Non-English Sources and Reference Management Software.”
After a two-month period, romanization was restored to WorldCat.org’s records. This brief moment reminds East Asian Studies scholars and enthusiasts that we must advocate for equal representation and even usability in technology platforms. These incidents at the intersection of technology and non-Roman script languages are common. Unfortunately, they create a self-fulfilling prophecy where we do not use such tools since they do not, cannot, or will not meet our needs. In turn, this leaves our perspective left out of future development cycles and potentially newer software and technology.