
In part 1 of this series, I provided a quick introduction to eScriptorium and the workflow associated with it. This post introduces digital text production for historical printing in Urdu using an annotated dataset of ~24,000 lines that I have prepared from 15 different texts published between the 1860s and 1940s. Furthermore, I offer OCR models based on this dataset to automatically segment and transcribe Urdu texts in eScriptorium, and by extension Kraken. Researchers and librarians looking to OCR historical Urdu print will find this work useful.
Urdu Script and Typography
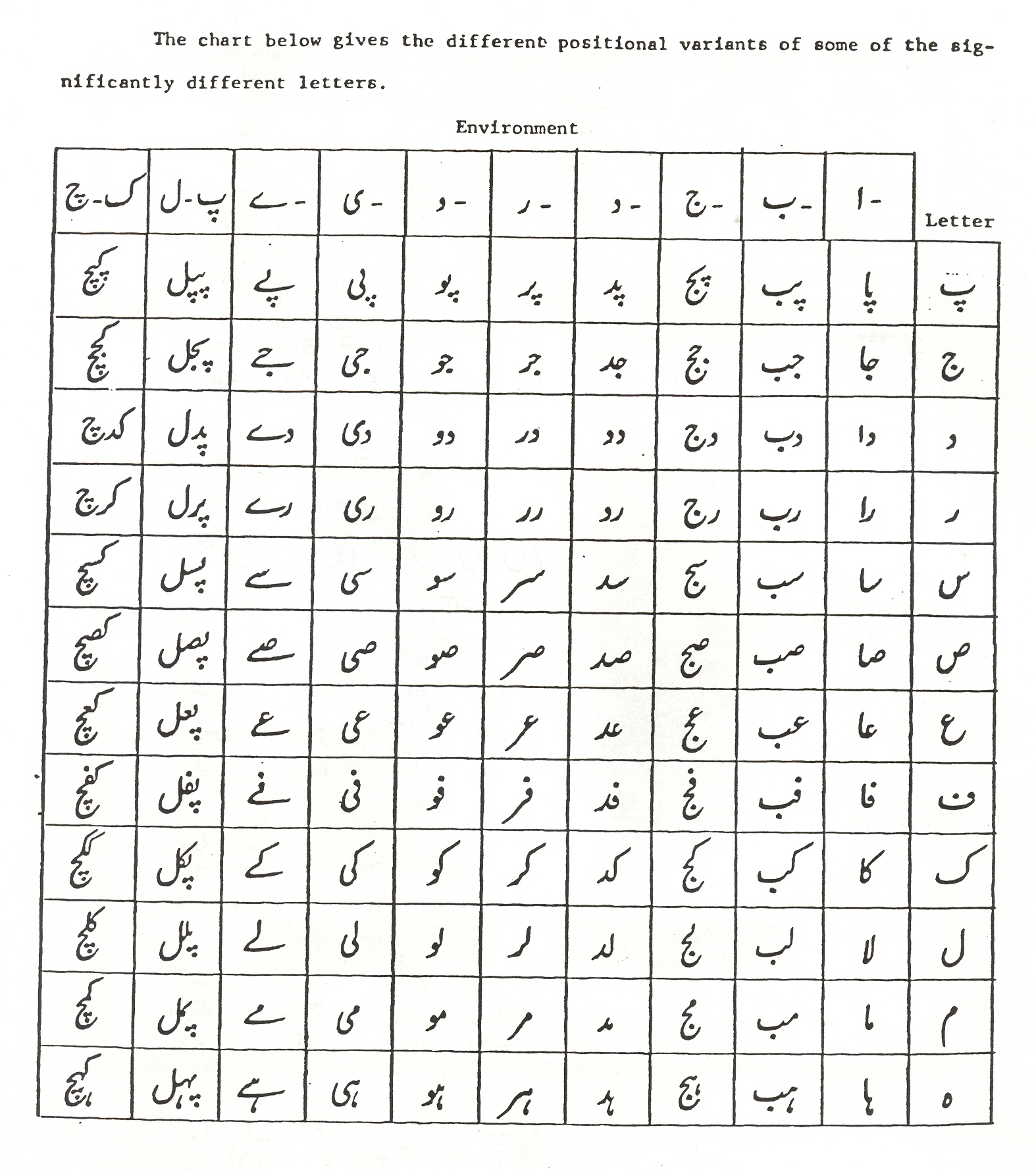
Urdu is mainly written in the nasta’līq style that values aesthetics over legibility. While Urdu letters do not have distinct case forms (small or capital), they can be divided into two major categories: letters that always connect to the next letter in a word, and letters that never connect. In terms of appearance, they can be organized into a handful of series or groups, where a set of letters have identical shapes but differ only in the number of dots (nuqṭa) they have.
| ا | |||||
| ث | ٹ | ت | پ | ب | |
| خ | ح | چ | ج | ||
| ذ | ڈ | د | |||
| ژ | ز | ڑ | ر | ||
| ض | ص | ش | س | ||
| ظ | ط | ||||
| غ | ع | ||||
| ق | ف | ||||
| ن | م | ل | گ | ک | |
| ے | ی | ء | ھ | ہ | و |
Despite this simplicity, Urdu has a large grapheme inventory, primarily because each letter, except the nine non-connector letters, takes three distinct shapes – initial, medial, and final – relative to their neighbor. Consequently, the combination of n letters in a ligature also contributes to this variability.
In practice, lines in a Urdu text hardly follow a solid baseline, and the words appear as slanted horizontals. As rigid y-axis guidelines are largely absent, the descender glyphs of a character in a particular line often merge with the ascender glyphs in the line below. Moreover, words are densely spaced, and the space between words may resemble space between non-connecting characters, which can be challenging even for humans, let alone a machine.

Digudaz (Volume 10, Issue 1-12) [1906]
Image: Endangered Archives Programme
Irregularities in the representation of particular glyphs, for instance using the choti-he as a variant of the do-chashmi he to create aspirated ligatures, irregular boundaries between nouns and their case markers, or variation in historical orthography further complicate the high degree of variability in Urdu typography. Lithography as a printing technology adds another layer of complexity as the appearance of letterforms is much more irregular in lithography compared to mechanical types.

Mazhab-e-Ishq (1843)
Image: Internet Archive
These factors combined with the complex document layouts of historical Urdu texts significantly limit automatic transcription of these texts at Character Accuracy Rates (CAR) in the high nineties.
Dataset Description
The Open Islamicate Texts Initiative (OpenITI) has prepared a dataset of ~10,000 lines for training Urdu nasta’lq recognition models. However, texts annotated in this dataset are printed with Monotype fonts, which is why a recognition model trained from it underperforms on historical Urdu printing.
In order to improve OCR efficiency for Urdu texts published between the 1860s and 1940s, I annotated a few pages from a collection of 15 texts, totaling ~24,000 lines. As these texts represent different typefaces in use for printing Urdu at the time, their annotations augur well for training serviceable OCR models. This sampling method of drawing training data from a variety of books, elsewhere described as the process of “training mixed models” (Springman and Lüdeling, 2017), provides the OCR models considerable coverage to efficiently adapt to the diversity of Urdu typefaces.
The dataset has three annotation layers. The first layer segments each page into logical text regions, and is stored in the <TextBlock> element of the ALTO-XML document tree. The second layer breaks down these regions into lines, which are recorded in <TextLine> element. Both <TextBlock> and <TextLine> are relevant for training segmentation models. Lastly, there is the transcription proper, provided in the <String> tag for each <TextLine>, and obligatory for training recognition models.

ALTO (XML) Document Tree
The transcription is diplomatic, i.e. it reproduces the text on the page as closely as possible, and checked twice to minimize transcription errors. Although I recreate diacritics as in the underlying documents, including signs for short vowels, it is possible to filter characters using a tool like choco-mufin in case you prefer to train recognition models without these characters.
Together, there are ~ 34,000 lines from 25 texts covering a wide variety of typefaces in Urdu, which I used to train OCR models for segmentation and recognition tasks. This is a work in progress, periodically updated at this GitHub repository.
Model Training
Training the recognition model from scratch took ~14 hours on a mid-tier RTX GPU. In comparison, fine-tuning the base model for new documents with 100-300 lines as examples from a new document can be done in under 10 – 20 minutes on a similar GPU. Fine-tuning on a standard CPU may take anywhere between 40 – 60 minutes. For details on fine-tuning OCR models in eScriptorium and by extension Kraken, see part 1 of this series or follow Kraken’s documentation.
Model Description
The base recognition model provided here generalizes at 94.6% CAR on the validation set. In practice, the model is likely to be less efficient for Urdu documents printed in typefaces significantly dissimilar to those seen during training. Here is an overview of its evaluation with Kraken’s test command.
=== report ===
1884212 Characters
45761 Errors
97.57% Accuracy
19701 Insertions
15062 Deletions
10998 Substitutions
Count Missed %Right
397149 5594 98.59% Common
1444619 22963 98.41% Arabic
41591 1877 95.49% Inherited
850 262 69.18% Latin
3 3 0.00% Devanagari
Errors Correct-Generated
5861 { } - { SPACE }
3563 { SPACE } - { }
1326 { ا } - { }
1184 { ی } - { }
843 { ہ } - { }
819 { } - { ی }
762 { م } - { }
750 { } - { ۔ }
749 { ر } - { }
707 { ن } - { }
704 { ۔ } - { }
688 { } - { ا }
627 { و } - { }
611 { ل } - { }
582 { ک } - { }
573 { ت } - { }
528 { س } - { }
505 { } - { ہ }
493 { } - { ن }
In its current state, the base model has a number of limitations. First of all, it transcribes texts published in the 1800s with lower confidence than texts from the 1900s. Additionally, word boundary errors are by far the most common error in texts transcribed with this model. This leads to either insertion of unwanted spaces or deletion of wanted spaces between words, otherwise called run-on errors and split errors.
In addition, the model transcribes similar looking characters such as ر , د , and و with lower accuracy. It also has trouble reproducing diacritics, especially in densely spaced characters. The material complexity of Urdu typography, where “words are often crammed irregularly into every available cranny for reasons of space and/or aesthetics” (F. W. Pritchett, web), is another major factor that hinders the model’s efficiency.
Typical Transcription Errors
As diacritics for short vowels are optional in Urdu, I also trained a recognition model with a version of the dataset that excluded these signs. My brief testing of the resulting model available here suggests that this approach may produce transcriptions with better Word Accuracy Rates (WAR) – a more meaningful unit for analyzing OCR efficiency for humanities research.
Applications of this Work
You can use this ongoing work in two ways. To OCR texts printed in a neatly laid out single column layout, particularly those printed after the 1900s with fairly consistent text blocks and fewer paratextual and ornamental features, Kraken as a standalone tool is enough to produce transcriptions with a CAR anywhere between the low to mid 90s. Kraken’s documentation provides examples for achieving this.
For more complex texts, eScriptorium is an invaluable tool. Once you have set up a document and imported text imagery, you can start segmenting the pages into text blocks or regions. Here, the default segmentation model in eScriptorium does a fairly good job, however it is likely to fail on multicolumn documents, a dominant feature in historical Urdu print. Drawing regions manually for multicolumn documents can be less time consuming here, at least until the model gets better at this task. Jonathan Robker has explained this part for Hebrew Manuscripts in this post.
Next, you can segment regions into lines with either the default model or a custom model that I have trained, and fix segmentation errors by following Jonathan’s post. However, instead of annotating the lines at the topline location as in the Hebrew example, use the baseline location for Urdu texts. For reference, check out the image below.

Example of Baseline Segmentation
Singāsan Battīsī Naẓm (1871)
Image: Universitätsbibliothek Heidelberg
You can now apply the recognition model on your text and even improve the model further by following part 1 of this series. To summarize, you can use the base recognition model to annotate a few pages of your documents in eScriptorium, fix transcription errors, and then use your transcriptions to fine-tune the base model. The resulting model trained on annotated examples of your text will be far more efficient at transcribing it.
In the next post, I will introduce another annotated dataset for historical Bengali print and we will dig deeper into eScriptorium’s workflow. Stay tuned!
2 thoughts on “eScriptorium: Digital Text Production for Urdu, Hindi, and Bengali Print, part 2”