
This is a guest post by Laurent Van Cutsem (Ghent University).
Part II: The Database of Medieval Chinese Texts: A Critical Overview
Even the most experienced scholars working with pre-modern Chinese textual witnesses are occasionally faced with graphs that they are unable to recognize immediately. Difficulties in this respect can either be caused by cursive forms, poor handwriting, or the use of rare demotic characters (suzi 俗字), simplified characters (jianhuazi 簡化字), archaic characters (guzi 古字), and so forth. These graphic variants, often grouped under the umbrella-term “variant characters” (yitizi 異體字),1 are typically contrasted with historical or modern “standard characters” (zhengzi 正字) sanctioned in lexicographical sources such as the Ganlu zishu 干祿字書 (Character Book for Seeking Official Emolument, 774), the Longkan shoujing 龍龕手鏡 (Hand Mirror of the Dragon Shrine, ca. 997), or the various “Tables of standard characters” (zhengzi biao 正字表) promulgated by the Ministry of Education 教育部 in Taiwan.
Two of the most commonly used tools to identify variant characters are the Jiaoyubu yitizi zidian 教育部異體字字典 (Dictionary of Variant Characters of the Ministry of Education) and dictionaries such as the Dunhuang suzidian 敦煌俗字典 (Dictionary of Demotic Characters from Dunhuang) of Huang Zheng 黄征. The former is limited in the sense that it primarily collects variants from historical lexicographical sources such as the Ganlu zishu or the Longkan shoujing mentioned above. The latter is limited by its printed format, which entailed a necessary selection of a limited set of representative variants from Dunhuang manuscripts.
The “Variants” module of the Database of Medieval Chinese Texts (DMCT)—which I introduced more broadly in my previous contribution—positions itself as a complementary tool to these useful resources. Not only does it cover a wide range of manuscripts (e.g., from the 5th to the 10th century, or belonging to different literary genres), but it also already includes a sufficiently large number of entries to help researchers better contextualize graphic variants encountered in the manuscripts that they are working on.
Overview of the “Variants” module of the DMCT
In origin, the “Variants” module of the DMCT is a byproduct of the “Texts” module of the same database as it was deemed necessary to integrate images of variant characters in the diplomatic TEI editions of the Dunhuang manuscripts for those graphs that had not yet been encoded as Unicode characters. The dataset presently contains a total of ca. 53,000 items and is expanding in parallel to the production of digital editions of manuscripts and other projects at the Ghent Centre for Buddhist Studies (GCBS) and the Dharma Drum Institute of Liberal Arts 法鼓文理學院 (DILA). Unfortunately, precisely because the DMCT developed by integrating different projects, the “images” of the variant characters contained in this dataset have been produced in different ways over the course of its development, from snippets of digitized manuscripts to digital reproductions or drawings, some of which were borrowed from the Jiaoyubu yitizi zidian.2 New entries, however, now consist exclusively of snippets of digitized manuscripts.

Figure 1: Homepage of the “Variants” module
As can be seen in Figure 1, the “Variants” database presents by default a tag cloud that reflects the various tags encoded for each variant entry (e.g., pressmark, name of the text, literary genre, date; see Figure 3) and which can be hidden if the user chooses to. Users can click on any given tag to filter the entries accordingly. However, at present, it is only possible to select one tag at a time.
Below the tag cloud is a general search box that allows users to search for a word or a traditional Chinese character across the DB. This search function only searches through the descriptive text contained in the various fields of the individual DB entries (e.g., standard characters or Unicode variants, date, comments; see Figure 3). Tags, on the other hand, do not seem to be included in this search function. For instance, whereas the “early Dunhuang manuscripts” tag is used for 1630 items, searching for “early Dunhuang manuscripts” returns only 13 items.
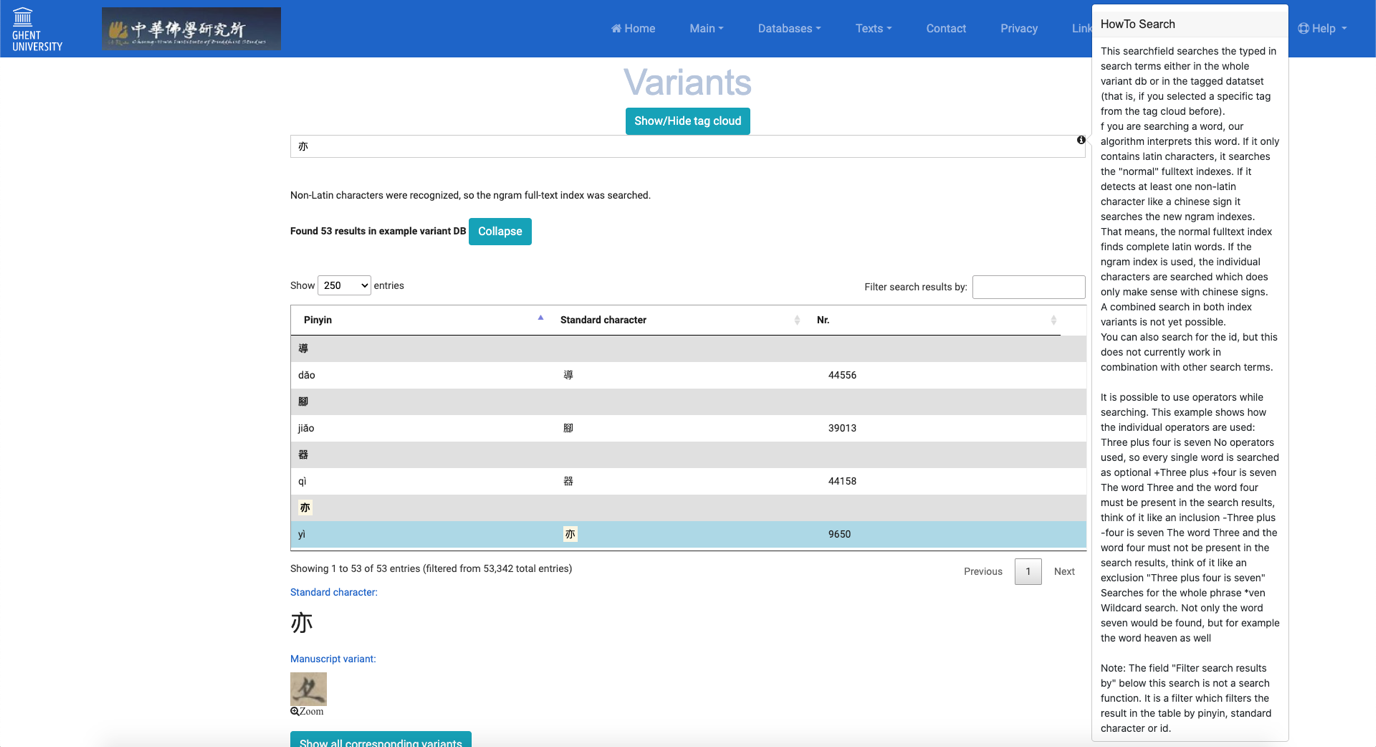
Figure 2: First part of the basic display of the “Variants” module
As shown in Figure 2, searching for the character “亦” (yì, “also, too”) using the general search box returns 53 results, among which the first three are not variants of “亦” but entries in which the standard graph “亦” appears in the “comments” section of these entries (see Figure 3). Search results are presented in a neat table which can be ordered by pinyin (default), “standard character,” or input number. The user can then select and go through the individual entries of variant character forms contained in the DB. At present, the DB does not allow users to filter their results a posteriori by clicking on one or more tags in the tag cloud. The only way to do this would be to first select a tag and then search for a given character in the general search box.
For the reasons explained above, it is in fact much more intuitive to use the “Filter search results by” box (located above the top-right corner of the table; see Figure 2) to search for the variant forms of a given modern standard character. Using this box to search for “亦” returns 50 results—that is, without the three additional entries returned by the general search box mentioned earlier. Naturally, users have to use “traditional standard characters” (guifan fantizi 規範繁體字; e.g., “礙” and not “㝵” or “碍”).

Figure 3: One “variant” entry of “亦” (by Wu Taoyu 吳韜玉; input by Christoph Anderl)
Once an entry is selected, users will find below the general table all relevant fields of information (Figure 3) containing:
- The “standard character”;
- An image or digital drawing of the variant character;
- A pinyin (with tones) transcription of the pronunciation of that character in Modern Standard Chinese;
- A transcription of the pronunciation of that character according to the Zhuyin fuhao 注音符號 system;
- An “alternative writing” field which occasionally contains variants already encoded in Unicode (e.g., 㝵 for 礙, ài, “to obstruct”);
- The “source in the manuscript”—that is, the exact reference in the manuscript;
- Date or time range of the corresponding manuscripts;
- If available, the corresponding identifier (ID) of the Jiaoyubu yitizi zidian;
- Comments by the contributor(s);
- The initials of the contributor(s) responsible for the entry, and the initials of the contributor(s) responsible for the input;
- The relevant tags; and
- Transcriptions in Old and Middle Chinese according to William H. Baxter and Laurent Sagart (2014).
Fields that were left blank by the contributor(s) do not show.
In addition to this basic display, the DMCT has recently implemented a convenient comparison tool which can help in the identification or contextualization of the variants. By clicking on the “Show all corresponding variants” button (see Figure 3), users are redirected to a page where they can more easily compare all variants collected in the DB (Figure 4).
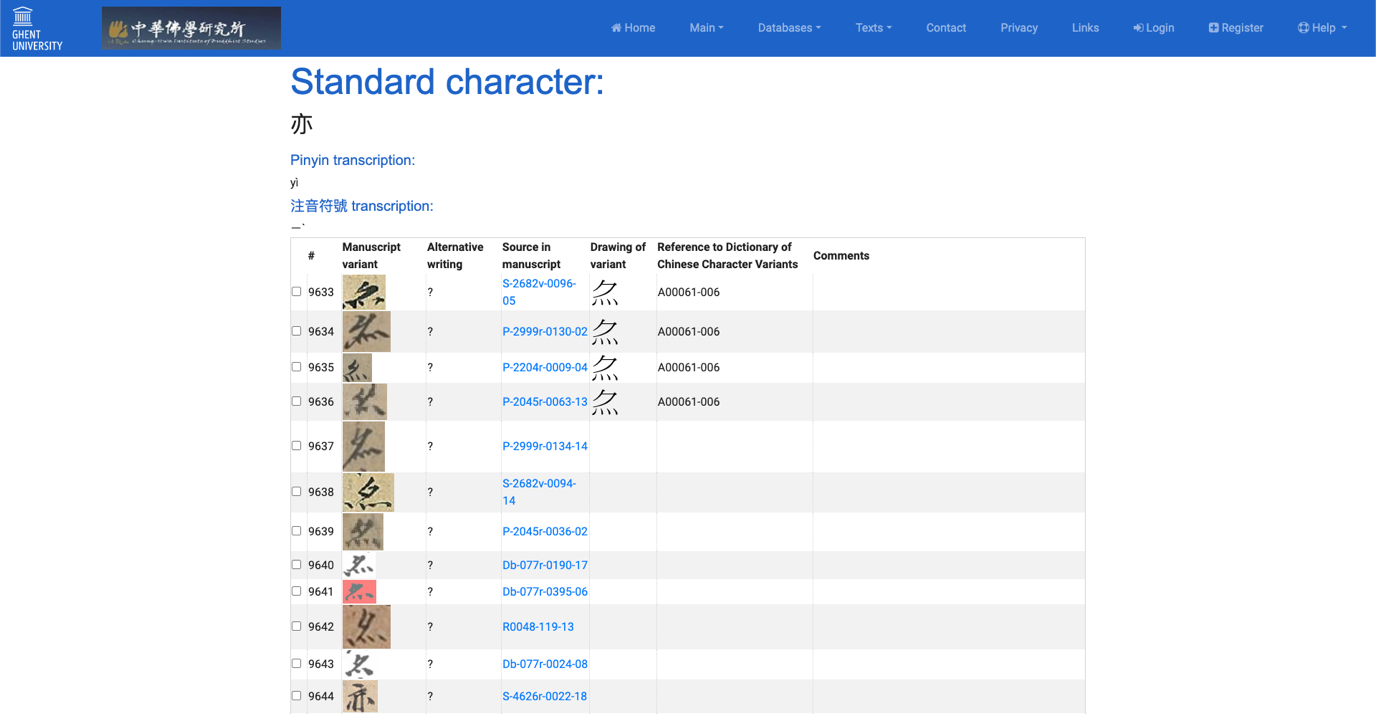
Figure 4: “Compare selected variants” page of the Variants module
Users can subsequently select specific items and click on the “Compare selected variants” button at the bottom of the page, which then opens a pop-up page with the relevant selection of variant forms. Note that a maximum of ten variants can be selected for comparison at a time. In the pop-up page (Figure 5), variants can be ordered in a specific way by sliding the images into the second table. Eventually, the output can be downloaded, although it is not clear whether these images can be used in scholarly publications.

Figure 5: “Comparison tool” pop-up page of the Variants module
In summary, the objectives and usage of the “Variants” module of the DMCT are relatively different from those of the Jiaoyubu yitizi zidian and dictionaries such as the Dunhuang suzidian. For instance, whereas the Jiaoyubu yitizi zidian allows users to identify variant forms based on character strokes or semantic elements (shoubu 首部) and additional strokes, the DMCT expects its users to have already formed an educated guess about the potential corresponding modern standard characters of the variants that they are faced with in the sources. This, then, can be put to test by examining the variant forms collected in the DB.
In addition, the fact that the “Variants” module already contains many graphic variants from a wide range of Dunhuang manuscripts (with additions from the 1245 woodblock edition of the Zutang ji 祖堂集) is commendable as this allows users to see that a given variant may have been relatively common in, for example, 6th century manuscripts.
Eventually, whereas the DMCT does not provide an “identifier” for graphic variants that are structurally similar, it does provide an “input number,” the exact references of the variants in the textual witnesses in which they occur, and, if digital editions of these witnesses have already been produced, a direct link to the line of the corresponding editions in the “Texts” module of the DB. This information can thus be used in scholarly publications or editions of Dunhuang manuscripts to support arguments regarding the identification of specific variant forms.
What could be improved?
- Although new entries in the “Variants” module of the DMCT all seem to be snippets of digitized manuscripts, the heterogeneous nature of the dataset—which as we have seen is due to the integration of previous projects—is not ideal. The database would probably benefit from harmonizing how variant characters are displayed in this module.
- The tagging system used in the DMCT could be more systematically organized and should ideally be curated. For instance, the “Sūtra Lecture Text” tag returns 2188 items, whereas the Chinese equivalent “講經文” returns 2281 results. Similarly, tags related to the date or time range of the variants include very different expressions such as “early Dunhuang manuscripts,” “5th c. variants,” “early 6th c. variants,” or “850–1000.” Although I understand that tags are input by individual contributors of the DMCT and perhaps answer to specific needs, the tagging function would benefit from a harmonization process, and it could certainly leave out superfluous terms such as “variants.”3
- The results table could perhaps integrate additional columns with information, for example, on the date or time range of the manuscripts to optimize the experience of the users who could then view only entries that are relevant for them (e.g., variants of the 9th century).
- The editors should at least state somewhere what is meant by “standard” and “variant” characters and explain exactly how the selection and classification were made.4
More generally, one element that would be of great interest to the scholarly community and which could be implemented in future (and perhaps past) entries of the “Variants” module would be to record the number and percentage of occurrences of a variant form in a given manuscript. Only under these conditions can we hope to have more solid data regarding the representativity of specific graphic variants in the Dunhuang context. However, I understand that such a laborious process would necessitate stable funding over the next few years.
Second, the data concerning the date or time range of the manuscripts from which the variants were collected could also be improved. Besides the “date” field of the entries, the editors could perhaps provide a comprehensive table of the manuscripts surveyed and explain the reasoning behind the dating of the manuscripts. Having an accurate date for manuscript copies is crucial if we wish to work towards a diachronic understanding of writing habits in the Dunhuang region. Similarly, if the editors have information concerning the place where the manuscripts were produced (e.g., Dunhuang, Chang’an), providing such detail would be a valuable addition for scholars of the Chinese script.
If these points are addressed in the future, the “Variants” module of the DMCT could not only be used as a useful tool for the identification and contextualization of graphic variants, but it would also open avenues for qualitative and quantitative research on variant character forms in the Dunhuang context and beyond.
Footnotes
- On variant characters, see, e.g., Galambos (2011; 2014; 2015), Huang Zheng 黄征 (2019), Qiu Xigui 裘錫圭 (1995; 2000), and Zhang Yongquan 張涌泉 (2015).
- See Anderl (2020, 350).
- On a related note, neither “Stein 2054” nor “Pelliot 2045” are the correct pressmarks of these manuscripts, although I am sure that the editors know this. The official pressmarks are “Or.8210/S.2054” (where “S.” might in fact not refer to “Stein” but to “scroll”) and “Pelliot chinois 2045” respectively. The pressmarks, however, could be abbreviated, according to the scholarly convention, to “S.2054” and “P.2045” to increase the readability of the tag cloud.
- Naturally, “standards” were not the same across regions and periods.
References
Anderl, Christoph. 2020. “Some Reflections on the Database of Medieval Chinese Texts as a Multi-Purpose Tool for Research, Teaching, and International Collaboration.” In Corpus-Based Research on Chinese Language and Linguistics, edited by Bianca Basciano, Anna Morbiato, and Franco Gatti, 341–60. Venezia: Ca’Foscari. https://doi.org/10.30687/978-88-6969-406-6/011.
Anderl, Christoph, ed-in-chief. 2023. “Database of Medieval Chinese Texts.” Ghent Centre for Buddhist Studies (Ghent University) and Chung-Hwa Institute of Buddhist Studies 中華佛學研究所. https://www.database-of-medieval-chinese-texts.be/.
Baxter, William H., and Laurent Sagart. 2014. Old Chinese: A New Reconstruction. New York: Oxford University Press.
Chinese Buddhist Electronic Text Association 中華電子佛典協會, ed. 2023. “CBETA Online Reader 線上閱讀.” https://cbetaonline.dila.edu.tw/. Last accessed 10 March 2022.
Galambos, Imre. 2011. “Popular Character Forms (Súzì) and Semantic Compound (Huìyì) Characters in Medieval Chinese Manuscripts.” Journal of the American Oriental Society 131, no. 3: 395–409.
Galambos, Imre. 2014. “Medieval Ways of Character Formation in Chinese Manuscript Culture.” Scripta 6: 49–73.
Galambos, Imre. 2015. “Variant Characters.” In Encyclopedia of Chinese Language and Linguistics, edited by Rint Sybesma, 4:483–84. Leiden: Brill.
Huang Zheng 黄征. 2019. Dunhuang suzidian 敦煌俗字典. 2nd edition. Shanghai 上海: Shanghai jiaoyu chubanshe 上海教育出版社.
Qiu Xigui 裘錫圭. 1995. Wenzixue gaiyao 文字學概要. Edited by Xu Tanhui 許錟輝. Taibei 臺北: Wanjuanlou tushu gufen youxian gongsi 萬卷樓圖書股份有限公司.
Qiu Xigui 裘錫圭. 2000. Chinese Writing. Translated by Gilbert Louis Mattos and Jerry Norman. Berkeley: Society for the Study of Early China.
Zhang Yongquan 張涌泉. 2015. Dunhuang suzi yanjiu 敦煌俗字研究. 2nd edition. Shanghai 上海: Shanghai jiaoyu chubanshe 上海教育出版社.
One thought on “The Database of Medieval Chinese Texts: A Critical Overview (part two)”