
This is a guest post by Jiajun Zou. See bio at the end of this post.
Find part one here.
Part II: Utilizing Provincial Gazetteers for Juren Dataset Compilation
The compilation of the juren dataset predominantly relies on provincial gazetteer sources, which account for a significant portion of the data. These sources document an original tally of approximately 98,000 individuals, with duplicate removal processes ensuring a more conservative count of at least 89,057 unique entries. This process involves eliminating duplicates based on name, province, and examination year. The shortfall in this dataset is in the Henan provincial records due to lost data in the provincial gazetteer. It is compensated by integrating records from the Tianyige collection (see Part I), culminating in a comprehensive dataset totaling 93,770 individual juren profiles.
Provincial Gazetteer Extraction Process
In contrast to the challenges faced with the Tianyige Ming provincial examination records, which required intricate OCR and image conversion solutions, provincial gazetteer sources are readily accessible in text format across various digital platforms. This accessibility simplifies the extraction process, allowing for a focused application of regular expressions for data analysis. The diversity in recording practices across provinces necessitated a creative and innovative approach to data extraction, facilitated through collaboration with ChatGPT.
Step 1: Source Acquisition
Provincial gazetteer records, unlike the specialized Ming provincial examination records from Tianyige, are widely available on the internet. Key repositories include the Daizhige depository on GitHub, Kanripo, Zhonghua wenku, and Wikisource. These platforms host editions of the Siku Quanshu, a comprehensive collection of Chinese texts, each containing an “Examination” section (选举志). This section lists examination degree holders, both civil and military, from the juren level upwards across various historical periods. Compiled during the Qing dynasty, these records encompass Ming dynasty juren and jinshi data, contingent on the compilers’ ability to source the information and subject to the possibility of recording errors by the compilers.
Among all the provincial gazetteers of the Qing dynasty, most are referred to as Tongshi (通史) or “general history” of a given province. Henan province posed a unique challenge, as its provincial gazetteers had lost a considerable amount of data, with many records declared “untraceable.” This significant data loss marked a notable challenge in the compilation of examination lists from the Ming and Qing dynasties, unmatched by any other provincial gazetteer. To mitigate this issue, I used records from the Tianyige collection (see Part I), which documented Henan juren up to the year 1571, and added them to the dataset. Similar challenges were encountered with other provinces, such as Jiangnan (now the Jiangsu and Anhui regions of China), where compilers occasionally acknowledged the inability to account for all candidates in a given year due to source restrictions.
Part II of the post is about illustrating this meticulous process of sourcing and compiling data from provincial gazetteers, coupled with strategic solutions to address missing data, particularly how I bypassed the issue of formatting challenges in the original sources, which would have resulted in inaccuracies. The solution I created was a combination of regular expression and website scraping techniques through ChatGPT.
Image 1: The Daizhige Depository on GitHub is a free and open source of ancient Chinese texts.

Image 2: The Zhonghua Wenku depository also hosts most of the Siku edition of ancient Chinese texts.

Image 3: The Wikisource depository also hosts most of the Siku edition of ancient Chinese texts.
Step 2: Deciphering the regular expression pattern
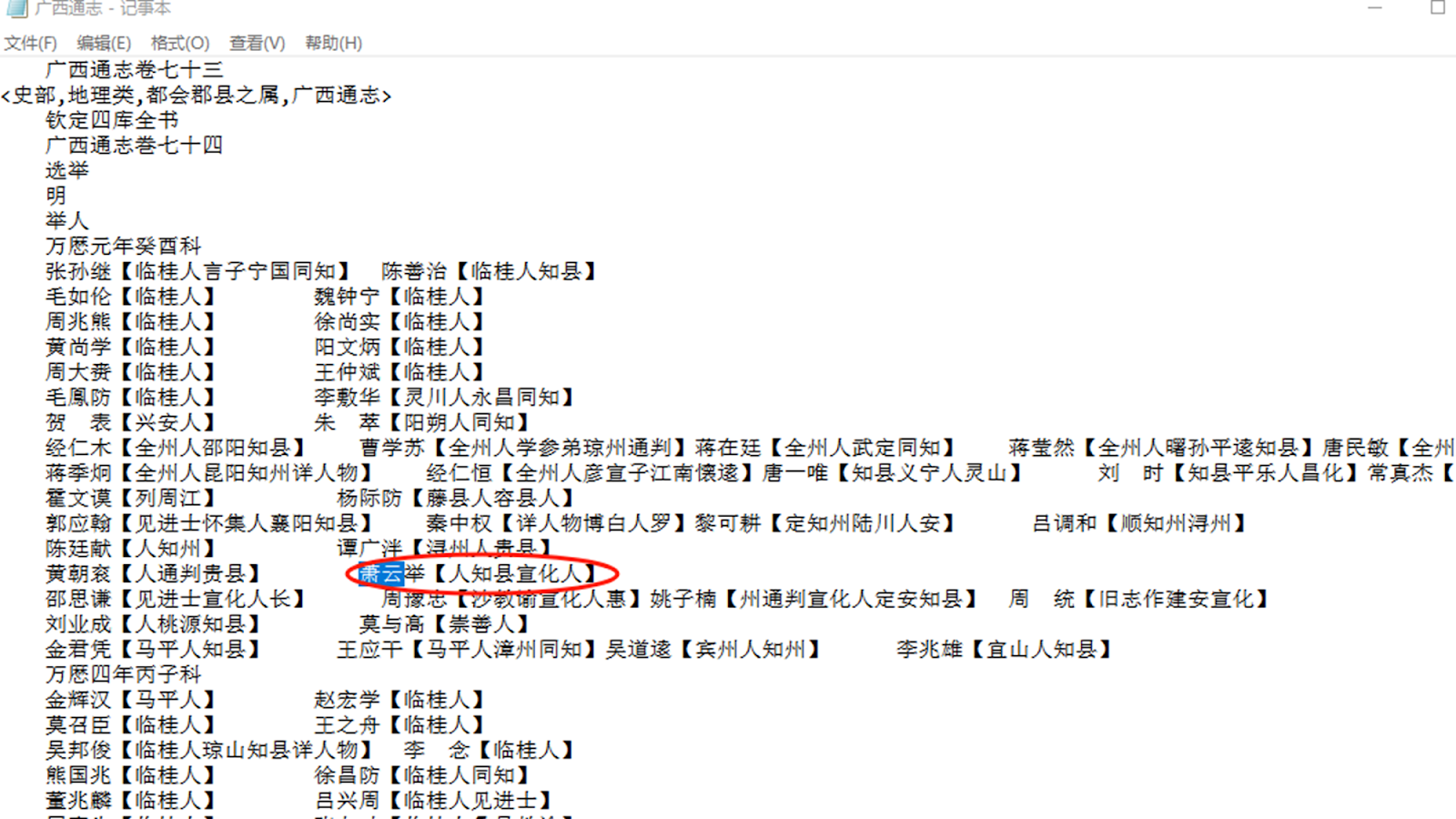
Image 4: A snapshot of Juan 74 from the Qing Provincial Gazetteer of the Siku Quanshu in Daizhige.
Simplifying Regular Expressions for Provincial Gazetteer Records
To illustrate the deciphering of regular expression patterns, we will use the Guangxi provincial gazetteer, specifically its 74th juan on the examination section obtained from Daizhige, as it presents a typical example of the format encountered in the downloaded texts. While the overall structure of these records is simpler compared to the Tianyige sources, certain anomalies require advanced regular expression techniques for correction. This is not to say that all provincial gazetteers use the same format. Indeed, the Fujian and Sichuan provincial gazetteers used entirely different formats that had unique challenges of their own, which we will not discuss here. Let’s examine the standard and exceptional patterns in these Guangxi records and how to address them.
Standard Pattern Recognition
A common pattern within these records is the combination of an exam year line followed by entries for individuals, each on a new line. For instance, the line “万厯四年丙子科” denotes the reign and exam year. Subsequent lines contain individual entries formatted as “Name 【Location人】”, where the name is followed by their location in brackets. This straightforward pattern applies to the majority of juren records, given the scant biographical details typically available.
Occasionally, entries include additional descriptors after the location, such as “程启后【宣化人射洪知县】”, which follows the pattern “Name 【Location人 Description】”. In this example, the individual is noted as a native of Xuanhua, Guangxi, who served as the magistrate of Shehong prefecture.
Addressing Formatting Anomalies
The primary challenge arises from formatting errors that lead to data misarrangement. For instance, entries like “萧云举【人知县宣化人】” or “周豫忠【沙教谕宣化人惠】” exhibit counterintuitive bracketed information. Such anomalies are not straightforward for automated processes to rectify, as they stem from the corruption of the source data during arrangement. This corruption likely occurred during the database compilation process, where lengthy descriptions within brackets were erroneously split and crowded into the brackets of adjacent entries. In other words, if a page displaying the text has only a given length and width, then an entity with a lengthy description may have information that requires more than one line. This person’s data then gets automatically squeezed into the next person’s entry and possibly squeezes the next person’s data into another person’s data. This series of chain reactions caused by one or two lengthy individual records nearly stalled my data compilation process.
Consider the example “邵思谦【见进士宣化人长】 周豫忠【沙教谕宣化人惠】”, where the description for the individual named Shao Siqian (邵思谦) should be “【宣化人长沙教谕】”, i.e., “Xuanhua person who is also a teaching assistant at Changsha city”. Here, the birthplace descriptor [宣化人] is misplaced within the bracket, and part of the description intended for 邵思谦 is incorrectly attributed to the next entry, Zhou Yuzhong (周豫忠). This disorganization is a result of the database’s mechanical formatting constraints, particularly when dealing with entries that include extensive descriptions. This was not an issue of source inaccuracy but formatting errors of modern-day database websites.
To mitigate these issues, I identified the affected pages and systematically substituted them with data from the more reliable Diaolong database. This is done by using word counts to locate those pages containing individuals with lengthy descriptions. This approach ensures the integrity and accuracy of the dataset, despite the challenges posed by the original source’s formatting limitations. After that, I proceed to find replacements for those pages.
Step 3: Leveraging Diaolong Database for Accurate Data Replacement
In addressing the formatting challenges encountered with the provincial gazetteer records from Daizhige, I turned to the Diaolong database, accessible through my university’s subscription. Diaolong, a repository of ancient Chinese texts, allows users to download up to 1,000 pages daily, providing ample scope for extensive data mining. However, the Diaolong download functionality introduces its own set of formatting complexities, often presenting lines with multiple entries where names, locations, and descriptions are intermingled. This complexity exacerbates the difficulty of applying regular expressions, as the amalgamation of multiple entities on a single line creates intricate combinations of datasets.
Navigating Diaolong’s Formatting Challenges
To circumvent the formatting issues inherent in both Daizhige and Diaolong sources, a strategic approach was required. The solution emerged in the form of Tampermonkey, a browser extension that enables users to execute custom scripts to enhance webpage functionality. Collaborating with ChatGPT, I developed a script capable of downloading webpage text while meticulously preserving the original formatting. This innovative approach facilitated the selective download of necessary pages from the Diaolong database, effectively addressing the word format discrepancies.
Implementing the Solution
Diaolong’s structured presentation of entries—allocating three lines per entity with the first line dedicated to the name and the subsequent lines to a combination of location and description—lends itself well to this method. By utilizing the script to maintain the integrity of this format, I was able to seamlessly integrate the corrected Diaolong data into the dataset. This method proved particularly useful for replacing problematic entries from Daizhige, ensuring the dataset’s accuracy without compromising the comprehensive coverage afforded by Daizhige sources that were free of formatting issues.
This step illustrates the importance of adaptability and ingenuity in digital humanities research. By leveraging advanced web tools and scripting, alongside the collaborative potential of AI platforms like ChatGPT, I was able to overcome significant obstacles in data formatting, paving the way for the creation of a reliable and historically valuable dataset.
As shown in images 5, 6, and 7, the default download option in Diaolong does not help. Neither would other popular database companies such as Airusheng or online depositories such as Daizhige or Wikisource be of any help either. They all have some kind of formatting errors in which the entities’ information is crowded together. This would be a non-issue if the Diaolong downloading option had just one entity per line, as I showed in Part I that it is possible to use regular expressions by first identifying the location and identity, which automatically leaves the “Name” as the last information in the line. But image 5 shows multiple entities in the same line with their names and descriptions at different lengths, not to mention that some individuals had missing information about their location and not all had a lengthy description. Clearly, an alternative solution is needed. This brings us to image 6 where the ChatGPT solution of a Tampermonkey script successfully detected that Diaolong had a way of allocating three lines to each entity regardless of how long their description may be, with the first line being the entity’s name. This fortunate discovery essentially replaced my regular expression effort and produced the record shown in image 6.

Image 5: Default Download of Diaolong Text which does not separate entities

Image 6: A Snapshot of Diaolong with the Tampermonkey Script Downloading Option

Image7 : A Snapshot of Provincial Gazetteeer records converting into Juren Dataset
Step 4: Expanding the Datasets
With a substantial portion of the Ming juren dataset compiled—approximately 80,000 entries from Qing provincial gazetteers and about 10,000, primarily Henan records, from Tianyige sources—the focus shifts towards validation and proofreading. The Ming provincial examination records, as official government documents, stand as the most reliable source, necessitating their prioritization over other materials for verification purposes. Since this is an ongoing process, different experiments and solutions are currently being tried and have not yet been finalized. Collecting as many original Ming provincial records as possible and using them as a cross-reference for other data sources such as provincial gazetteers allows us to ensure the maximum reliability of the dataset. The details in terms of how to further correct and ensure the reliability of nearly 100,000 juren in my records are still being investigated with different strategies and ideas in experimentation, which we will not have the time to discover in depth yet.
Expanding the Dataset:
- Global Library Collections: The digitization of collections by libraries worldwide presents an opportunity to incorporate additional provincial examination records into the dataset. From the National Library of China to the Library of Congress, these digitized provincial examination records are helping academics expand their datasets. With advancements in OCR technology and the availability of APIs tailored for ancient Chinese texts, such as Gujicool and Kandian OCR, the process of digitizing and analyzing these records is becoming increasingly feasible.
- Kandian OCR: Utilizing free APIs like Kandian, which offers up to one thousand pages of free OCR, could significantly aid in processing the remaining Ming provincial examination records. These records, numbering around 457, with 370 already included from Tianyige sources, represent a vital resource for cross-referencing and enhancing the dataset’s accuracy. With an average juren list of about 4-5 pages per examination record, this will account for an additional 400-500 pages of OCR for some 8000-10000 additional Ming juren from provincial examination records. In Image 8, I showed a GitHub repository called “Yingwen OCR,” which is a little-known Python and PyQt5 tool that lets users enter the Kandian API for processing OCR of ancient texts. In the near future, I will modify it such that batch processing of hundreds of images will be possible.
Supplementary Sources:
- Shaanxi Steles: The steles of Shaanxi juren, preserved and digitized by the National Library of China, offer an alternative and authoritative source of juren listings specific to Shaanxi province. While these steles provide valuable supplementary data, the challenges of OCR on such materials and the potential need for higher-resolution images may necessitate field visits to Shaanxi museums for optimal data capture.
This multi-faceted approach to verification and expansion of the juren dataset underscores the complexities of working with historical sources. It highlights the need for meticulous cross-referencing, the adoption of advanced digital tools, and the potential integration of unique and authoritative sources to ensure the dataset’s comprehensiveness and accuracy.

Image 8: Snapshot of Github tool Yingwen OCR using Kandian API

Image 9 is a snapshot of the Shannxi Stele in the Digital Archive of National Library of China
Conclusion
The compilation of the Ming juren lists represents a significant achievement in the field of prosopography, documenting an unprecedented number of individuals within Chinese historical studies. Juren, as provincial examination degree holders, occupy a unique position in the societal and governmental hierarchy. They are distinguished from the Jinshi, who have attained the highest echelons of political and educational influence, by their intermediary status. Despite their achievements, a large majority of Juren do not advance to the Jinshi level, making their contributions and experiences a less explored facet of Chinese history.
The Ming dynasty’s juren represent one of the largest cohorts within this scholarly classification, with the Qing dynasty potentially surpassing this with an estimated 150,000 juren. The endeavor to digitize and organize the records of Qing juren looms as a feasible future project, bolstered by the ongoing digitization efforts of libraries, advancements in AI technology, and the collaborative spirit within the academic community.
This extensive body of juren, spanning both the Ming and Qing dynacies, played pivotal roles in governing China through half a millennium, up until the early twentieth century. The exploration of their identities, origins, and contributions opens up new avenues for understanding China’s rich historical tapestry. Different visualizations such as map or relational networks as well as quantitative potential for scholars interested in society, politic, economic and history. My dissertation, in conjunction with my collaborative work with the China Biographical Database (CBDB) project at Harvard, aims to enrich the narrative surrounding juren. By providing comprehensive and reliable data on these individuals, we aspire to uncover and share the nuanced stories of this significant yet underrepresented group in the study of Chinese examinations and society. As we enter into the age of artificial intelligence where human and machine collaboration is vital, this post showcases the possibility of overcoming old challenges with new tools and ideas.
____
Author Biography: Jiajun Zou is a Ph.D. candidate in History at Emory University. His dissertation examines the provincial examination candidates of the Ming dynasty, focusing on regional performance disparities. He argues that the outcomes of these examinations are random and that regional performance gaps are influenced by non-human factors such as geography and transportation. Zou poses a simple yet crucial question: Why are powerful examination centers found only in certain southern provinces and not elsewhere in China?
