
Background
Historical Chinese texts and source notes, preserved in various forms including rare books, special collections, and modern academic databases, present unique challenges for information extraction. These sources often contain a combination of classical Chinese passages with modern annotations, references, and explanatory notes, making it particularly complex to interpret and analyze systematically.
Our team, the Chinese Culture and Heritage WikiProject group, encountered these challenges while working on a Linked Data (LD) project focused on Chinese historical places. Linked Data requires structured triples (subject-predicate-object statements), but extracting this information from mixed Chinese source notes proved challenging. We worked with historical source notes from the China Historical Geographic Information System (CHGIS), developed by Harvard University and Fudan University. A typical CHGIS source note might begin with a classical Chinese reference about a historical location, followed by modern Chinese annotations explaining its contemporary location, and conclude with scholarly citations from both modern and classical sources. This multilayered structure, while rich in information, poses significant challenges for systematic data extraction. This led us to explore the potential of generative AI for LD triple extraction, as it could potentially handle both classical and modern Chinese text formats simultaneously.
LD Triples Extraction
Source notes from the CHGIS database describe historical place names, administrative changes, and temporal information. For example, a source note about Anguo xian (安国县), a historical county in China, can be found in the CHGIS database as follows:
安国县(前221-公元13年) 秦县。
⑴治所在今河北安国县祁州镇东南的东安国城。
⑵秦属恒山郡。西汉先后属中山国、郡,新莽时改名兴睦县。
⑶ ⑴后晓荣:《秦代政区地理》:“1971年山西榆次王湖岭四号墓出土三晋古玺‘安国君’印。榆次在战国时属赵地,故此印可断为战国赵封君印。……又《汉志》中山国安国,‘莽曰兴睦’。《清一统志》:‘故城在祁州南。’二者互证,秦恒山郡置安国县,其故址在今河北省武垣县西北。”(社会科学文献出版社2009年版,第355页。)
⑵河北省地方志编纂委员会编:《河北省志》第2卷《建置志》,河北人民出版社,1993年,第25页。
⑶《汉书》卷28下《地理志下》,第6册,第1632页。 按:据《汉书》卷99中《王莽传中》:天凤元年(14年),“郡县以亭为名者三百六十,以应符命文也”。又曰:郡有内郡、近郡、边郡,“合百二十有五郡。九州之内,县二千二百有三”。(12册,4136—4137页)据此,姑作县在新莽天凤元年(14年)改名。”
The expected LD triples (Subject > Predicate > Object) and their corresponding qualifiers from the above source note is described as follows:

The Experiment
LLMs are known for their ability to extract data from text and process multilingual prompts and outputs. We therefore investigated whether LLMs could extract LD triples from Chinese texts using Chinese instructional prompts. We experimented with nine leading Large Language Models (LLMs): Meta Llama 3.3, Anthropic Claude 3.5 Sonnet, OpenAI ChatGPT 4o, Google Gemini 1.5, Baidu ERNIE 3.5, Baidu ERNIE 4.0, DeepSeek, 01.ai Yi-Large, and Alibaba Qwen-Max.
Our goal was to use few-shot prompts to extract triples using a defined set of predicates (dynasty, located in the administrative territorial entity, merged into, replaced by, replaced, separated from) and qualifiers (start time, end time, stated in, reference URL). Through iterative testing and refinement, we developed a prompt to guide LLMs in performing triple extraction. Our final prompt is as follows (click to enlarge):

The English translation for the instructions is as follows:
Your task is to extract triples about historical place names from a given book text. Please follow these rules:
1. Identify the place name entity as the subject
2. Only these predicates are permitted: dynamic, located in the administrative territorial entity, merged into, replaced by, replaced, separated from
3. Add corresponding qualifiers to each triple: start time, end time, stated in, Reference URL
4. Use AD for years, add “BCE” for BC.
5. All triples must contain Reference URL
6. Refer to the following examples for the output format.
The prompt instructs LLMs to extract LD triples based on specific predicates and qualifiers while following formatting guidelines. We included two input/output pairs as examples to demonstrate the expected JSON-like data structure. Following these examples, we append the source note for which we want the LLM to generate triples:
数据获取链接:https://maps.cga.harvard.edu/tgaz/placename/hvd_40096
安国县(908—977年)治所
梁开平二年(980年)改临安县为安国县,属杭州。①治所今浙江临安市北高乐②。宋太平兴国三年(978年)复名临安。③
①《新五代史》卷60《职方考》:吴越时有杭州。(第3册,727页)《旧五代史》卷150《郡县志》:“杭州临安县,梁开平二年正月,改为安国县。”(第6册,2018页)
②见临安县(688——709年)条注②。
③《舆地广记》卷22《两浙路上》:临安县“吴越王钱鏐,其县人也。鏐既贵,以素所居营为安国衣锦军。鏐归宴故老,山林皆覆以锦。梁改临安县曰安国县,以尊之。皇朝太平兴国三年,复曰临安。”(商务印书馆,丛书集成本,第3册,232页)《宋史》卷88《地理志四》临安府:“临安县,钱鏐奏改衣锦军。太平兴国四年,改顺化军,县复旧名。”(第7册,2174页)《宋志》所述不详,从《舆地广记》。
Since each LLM in our experiment has its own API, we developed a Python script to consistently feed identical prompts and CHGIS source notes to all models.
Results
The LLMs we tested all produced outputs that deviated to varying degrees from our manually-produced expected results. We evaluated these outputs using eight criteria that categorized different types and severities of errors:
| High-severity Errors: directly affect the factual accuracy and completeness of the output |
| – Missing a triple: a relevant triple that should have been generated is missing entirely. If a whole triple is missed, the qualifiers that should be included in the triples are not counted towards missing a qualifier. – Incorrect triple: a triple is generated, but it is factually incorrect or does not logically align with the input. – Incorrect qualifier value: the generated qualifier value is factually incorrect or does not align with the context or logic of the input. |
| Moderate-Severity Errors: impact precision and contextual appropriateness without fundamentally altering accuracy |
| – Suboptimal object value: the object value in the generated triple is technically correct but not the best or most appropriate expression for the context. – Unsupported/redundant object value: the generated object value is valid in isolation but irrelevant, unnecessary, or redundant in the given context. – Missing a qualifier: a qualifier that provides essential additional context or detail for a triple is missing. |
| Low-severity Errors: affect detail, clarity, or efficiency but do not compromise the core correctness or completeness of the triples. |
| – Suboptimal qualifier value: the qualifier value is correct but not the most appropriate, precise, or preferred representation. – Unsupported/redundant qualifier value: the qualifier value is unnecessary, irrelevant, or adds no meaningful value to the triple in the given context. |
The following table tabulates the total count of different types of errors found in the output of each LLM:
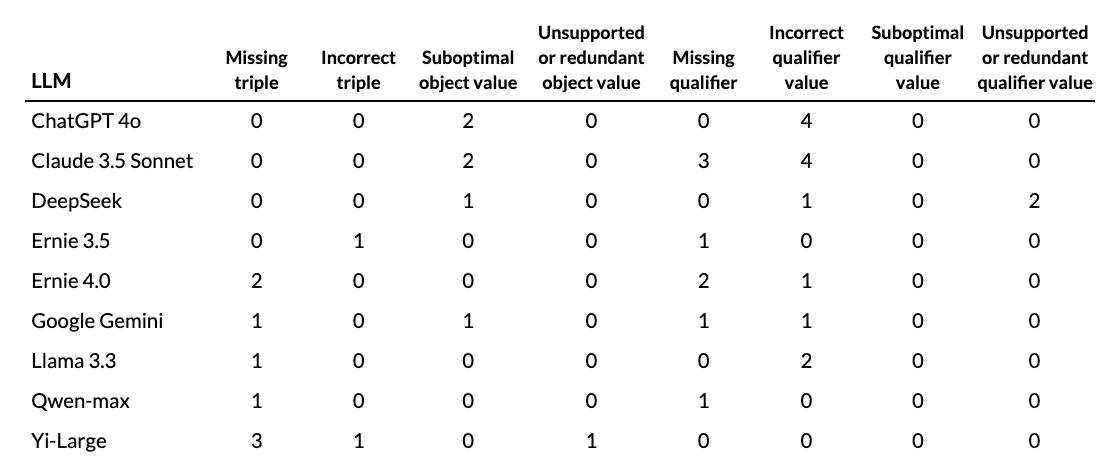
To compare the performance of the nine LLMs in a meaningful way, we developed a quantitative evaluation system. In the absence of established benchmarks for triple extraction quality, we created a weighted scoring system based on error severity:
- High-Severity Errors: 3 points per error
- Moderate-Severity Errors: 2 points per error
- Low-Severity Errors: 1 point per error
The total weighted score represents each model’s severity-adjusted error count, with lower scores indicating better performance. The error scores for each LLM in our extraction task are as follows:

ERNIE 3.5 and Qwen-Max achieved the best performance with the lowest weighted error scores of 5. DeepSeek followed closely with an error score of 7. In contrast, Claude 3.5 Sonnet received the highest weighted error score of 22, stemming from four high-severity and five moderate-severity errors. ChatGPT 4.0 and Yi-Large showed moderate performance with weighted scores of 16 and 14, respectively. Notably, we observed an unexpected performance gap between ERNIE 3.5 and ERNIE 4.0, despite both models being developed by Baidu.
Conclusion
While LLMs can extract triples from classical Chinese text using Chinese instruction prompts, our study revealed varying degrees of inaccuracies and errors across models. Therefore, human-in-the-loop processes and expert review remain essential for output validation and correction.
Notably, our experiment suggests that LLMs developed by Chinese companies (such as Baidu’s ERNIE and Alibaba’s Qwen) generally achieve lower error scores when following Chinese prompts to extract triples from classical Chinese text, compared to their Western counterparts (like OpenAI’s ChatGPT and Google’s Gemini). Although the exact reasons remain unclear, we hypothesize that these models’ superior performance stems from training on larger corpora of Chinese text, enabling better comprehension of Chinese instructions and classical Chinese nuances. A follow-up study using English prompts with identical instructions could reveal whether Western models perform better under those conditions.
Based on our findings, ERNIE and Qwen appear ideal for triple extraction in our Linked Data project, as their lower error rates in both quantity and severity minimize the need for manual corrections. Our future work will focus on several areas:
- Refining prompting strategies
- Collaborating with historians and classical Chinese experts
- Implementing controlled vocabularies like GeoNames to enhance accuracy and consistency
- Investigating generative AI methods for evaluating LLM results to streamline validation
Our ultimate goal is to integrate these LLM-generated triples into larger Linked Data projects, making historical information more accessible and interconnected. This project demonstrates generative AI’s potential to unlock information within classical Chinese texts, creating new research opportunities and deepening our understanding of Chinese history and culture.
Dr. Eric H. C. Chow is an independent consultant specializing in the application of Artificial Intelligence and Large Language Models for the GLAM (Galleries, Libraries, Archives, and Museums) sector in Asia and North America. He is also working as a part-time digital specialist at the Asia Art Archive. Most recently, he served as the Digital Scholarship Manager at Hong Kong Baptist University Library, focusing on development of digital archives and digital humanities tools.
Greta Heng is a Cataloging and Metadata Strategies Librarian at San Diego State University. Her research interests include linked open data, semantic web, identity management, and information search behavior.

One thought on “Evaluating LLMs for Linked Data Extraction from Chinese Texts: A Comparative Analysis”