
This post was written together with Sai Deng (Metadata Librarian, University of Central Florida) and Lihong Zhu (Head of Library Technical Services, Washington State University).
Facing the dual challenges of library staffing shortages and the complexity of cataloging Chinese materials, we set out to create a practical solution. In this post, we introduce a multilingual subject analysis tool we’ve developed — combining large language models, vector databases, and multilingual embeddings. Read on to see the potential of transforming cataloging workflows and supporting East Asian librarians.
Introduction
In modern library cataloging systems, each item in a catalogue has its own MARC (Machine-Readable Cataloging) record for storing its metadata. Among the various fields in a MARC record, one specific field is for inputting the topical heading of the work being described. Careful analysis of the subject of a work and accurately inputting subject headings in the MARC record is vital for enhancing library resource discoverability.
Subject analysis involves assigning appropriate descriptors to content, facilitating efficient retrieval and accurate representation. In academic libraries, especially those with a focus in Chinese text collections for East Asian studies, catalogers are tasked to accurately analyze the subjects of Chinese source materials for facilitating effective research and scholarship in Sinology. Their cataloging efforts enable sinology scholars to effectively discover and retrieve Chinese source materials. Catalogers also utilize standardized subject heading vocabularies, such as the Library of Congress Subject Headings (LCSH) or Faceted Application of Subject Terminology (FAST), to ensure consistency across catalog records, aiding in the collocation of related materials.
However, the vast and nuanced nature of knowledge and practices in Chinese culture requires catalogers to be familiar with diverse subjects in Chinese history and culture to accurately reflect a work’s content. Furthermore, the difficulty in hiring librarians with adequate foreign language expertise to serve the needs of large academic libraries has been a concern for a long time. Compounding to this problem, academic libraries worldwide are confronting significant budget cuts, leading to reductions in staffing and resources. Financial strain has only exacerbated the shortage of multilingual catalogers, as hiring specialized staff becomes increasingly challenging.
To address these challenges, many academic libraries are exploring ways to integrate large language models (LLMs) into their cataloging workflow. Such integration makes sense, given that LLMs specialize in linguistic processing, aligning naturally with cataloging tasks that fundamentally involve content analysis, including subject interpretation and metadata assignment.
Library of Congress Subject Headings (LCSH)
Dr. Kwok-leong Tang from Digital China Initiative at Harvard University has recently created an experimental GPT “LCSH Recommendation for East Asian Librarians” which is a chatbot-like tool designed to assist catalogers by suggesting LCSH based on a work’s title, abstract, table of contents, (or even images of the table of contents, abstract, and summary for the material uploaded to the chat interface) for East Asian materials. This tool leverages the predictive capabilities of LLMs to generate potential LCSH, offering a starting point for subject analysis. A Chrome browser extension of similar function was also developed by Dr. Tang.
LCSH consists of a controlled vocabulary of main headings that may be assigned alone or in combination with subdivisions. Subdivisions may themselves be further subdivided. LCSH has four categories of subdivisions: topical, form, chronological, and geographical subdivisions. Furthermore, LCSH is primarily a pre-coordinated controlled vocabulary, meaning that subject headings are constructed in advance to represent specific, complex topics as a single heading. For example, a book discussing architectural design of the Sui Dynasty can be represented by the pre-coordinated LCSH subject heading:
Architecture — China — History — Three kingdoms-Sui dynasty, 220-618
https://id.loc.gov/authorities/subjects/sh2015001441.html
Only a fraction of all possible heading-subdivision combinations are explicitly listed in the LCSH controlled vocabulary list. Therefore, catalogers can also combine what is called “free-floating subdivision” to more accurately describe a work. However, the application of free-floating subdivisions follows complex and often subtle rules and guidelines (such as a specific ordering of subdivision terms). This poses significant challenges not only for inexperienced catalogers attempting to master LCSH assignment but also for LLMs. LLMs, while adept at content analysis and generating individual headings, do not inherently possess the structured understanding required to navigate the intricate rules and hierarchies of LCSH, such as the appropriate ordering of subdivisions. Consequently, the outputs from LLM-based LCSH assignment tools should be viewed as recommendations rather than definitive assignments. Human oversight remains essential to ensure that subject headings are accurately and correctly applied according to LCSH rules.
Faceted Application of Subject Terminology (FAST)
In response to the complexities of applying LCSH, particularly its intricate free-floating subdivision rules, the Faceted Application of Subject Terminology (FAST) was developed collaboratively by OCLC Research and the Library of Congress. FAST retains LCSH’s rich vocabulary but simplifies its structure and use. It is now being gradually adopted by academic and national libraries around the world. FAST organizes subject data into nine separate categories, or facets: Personal Names, Corporate Names, Meeting Names, Geographic Names, Events, Titles, Time Periods, Topics, and Form/Genre. These facets can be used together or independently, depending on the needs of the catalog record.
All FAST subject headings are linked to authority records — standardized, pre-approved forms of names or terms maintained in a central database. This ensures consistency and eliminates the need for catalogers to manually piece together complex headings from multiple parts, as they would with LCSH. Because of this, assigning FAST headings becomes a straightforward process of selecting appropriate terms from a controlled list, rather than constructing them from scratch. This simplicity also makes FAST particularly well-suited for integration with LLM‑based recommendation tools.
Taking this into account, and inspired by the LCSH recommendation GPT previously mentioned, we have created a FAST recommendation GPT available on the OpenAI platform.
Screenshot of our FAST Recommendation GPT
The controlled vocabulary for FAST topical subject headings is available for download directly from the OCLC website. Utilizing this dictionary, we constructed a vector database — a specialized database designed to store data as high-dimensional numerical representations known as embeddings. These embeddings capture the semantic meaning of text, enabling efficient similarity searches based on context rather than exact keyword matches. We employed OpenAI’s text-embedding-3-small model to generate embeddings for every FAST topical subject heading (approximately 486,000 in total at the time of this writing). This embedding model is recognized for its high-quality, multilingual capabilities — including support for Chinese — and its cost-effectiveness, making it suitable for large-scale applications involving tens of thousands of subject headings.
The vector database then serves as the foundation for a Retrieval-Augmented Generation (RAG) system. In this framework, when a user submits a query — such as the title and abstract of a book — the system retrieves semantically relevant FAST headings from the vector database and incorporates them into the user response. Thanks to the multilingual capabilities of OpenAI’s text-embedding-3-small model, the system can effectively retrieve pertinent FAST headings even when the query is in Chinese, as the embeddings capture semantic meaning across languages. By integrating these retrieved headings into the LLM’s input, the RAG system can produce responses that are grounded in authoritative subject terminology. This approach can reduce the likelihood of the LLM generating irrelevant or incorrect subject headings (known as hallucinations). This approach was initially applied to the University of Central Florida’s AI-assisted cataloging experimental project in assigning FAST headings to its theses and dissertations as well as some non-English materials.
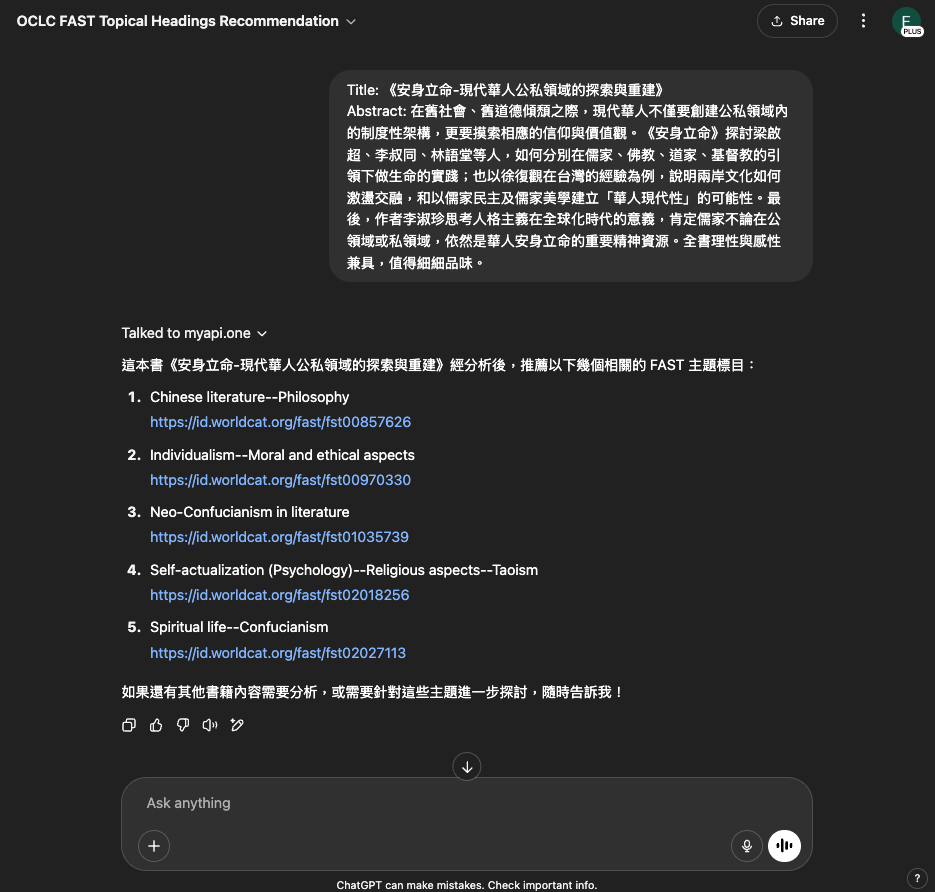
The following examples illustrate the practical application of our GPT, showing the FAST recommendation for three sample Chinese book titles and abstracts / table of contents:
Book 1
Title: 《安身立命-現代華人公私領域的探索與重建》
Abstract: 在舊社會、舊道德傾頹之際,現代華人不僅要創建公私領域內的制度性架構,更要摸索相應的信仰與價值觀。《安身立命》探討梁啟超、李叔同、林語堂等人,如何分別在儒家、佛教、道家、基督教的引領下做生命的實踐;也以徐復觀在台灣的經驗為例,說明兩岸文化如何激盪交融,和以儒家民主及儒家美學建立「華人現代性」的可能性。最後,作者李淑珍思考人格主義在全球化時代的意義,肯定儒家不論在公領域或私領域,依然是華人安身立命的重要精神資源。全書理性與感性兼具,值得細細品味。
FAST recommendations:
Chinese literature — Philosophy
https://id.worldcat.org/fast/fst00857626
Individualism — Moral and ethical aspects
https://id.worldcat.org/fast/fst00970330
Neo-Confucianism in literature
https://id.worldcat.org/fast/fst01035739
Self-actualization (Psychology) — Religious aspects — Taoism
https://id.worldcat.org/fast/fst02018256
Spiritual life — Confucianism
https://id.worldcat.org/fast/fst02027113
Book 2
Title: 宋明儒学中的”身体”与”诠释”之维
Table of Contents: 上编, 身体之维: 第1章, 回到身体:当代思想中的身体转向与儒学研究–第2章,身体之为“窍”:宋明儒学中的身体存在论建构–第3章,“身不自身”:罗近溪身体论发微–第4章,“侧隐之心”、“他者之痛”与“疼痛镜像神经元”–第5章, “心”与“腔子”:儒学修身的体知面向–第6章,宋明儒学中的“镜喻”–下编,诠释之维:第7章, 朱子读书法:诠释与诠释之外–第8章,“四句教”的三次辩难及其诠释学义蕴–第9章,儒学经传中“怀疑”与“否定”的言说方式:以王阳明、陈确的《大学》辨正为例–第10章,“亲民”抑或“新民”:从传统到现代
FAST recommendations:
Chinese language — Philosophy
https://id.worldcat.org/fast/fst00857500
Human body (Philosophy)
https://id.worldcat.org/fast/fst01730063
Mind and body — Philosophy
https://id.worldcat.org/fast/fst01022001
Philosophy, Chinese — History and criticism
https://id.worldcat.org/fast/fst01060921
Philosophy, Chinese — Methodology
https://id.worldcat.org/fast/fst01060922
Book 3
Title: 文咸街里 : 東西南北利四方
Abstract: 本書匯聚多位大學學者和歷史專家, 以南北行聚集地的上環文咸東, 西街為中軸, 講述19世紀中起, 香港與海內外不同地區的交通與聯繫. 由於文咸街臨近三角碼頭, 方便船隻上落貨物, 除了本身的廣府人, 更吸引了從潮州, 福建, 上海, 山東等地而來的商人買賣海味, 大米, 藥材等貨物. 原本南北行是指華南與華北間的貿易, 後來範圍擴大, ‘南’至東南亞, ‘北’至日本. 與此同時, 美澳加等地先後發現金礦, 時稱’金山’和’新金山’, 大量華人勞工(俗稱’豬仔’)通過香港金山莊橫渡太平洋, 這些四面八方的貿易往來與聯繫, 日後更帶動了香港船務運輸, 出入口轉運, 華僑匯兌, 外匯找換等行業發展, 是香港聯繫東西方世界的歷史見證.
FAST Recommendations:
Chinese — Commerce
https://id.worldcat.org/fast/fst00857174
East-West trade — History
https://id.worldcat.org/fast/fst00901096
International trade — History
https://id.worldcat.org/fast/fst00977141
Port districts — History
https://id.worldcat.org/fast/fst01072010
Trade routes — History
https://id.worldcat.org/fast/fst01153854
Conclusion
Our experiment demonstrates the promising potential of integrating LLMs and vector databases into subject analysis workflows, including Chinese-language materials in academic libraries. By leveraging multilingual embeddings and Retrieval-Augmented Generation (RAG) pipelines, the system can generate recommendations for FAST subject headings, improving both the efficiency and consistency of metadata creation. The approach provides a scalable solution for institutions facing challenges in staffing and linguistic expertise, offering support tools that can augment human cataloging efforts. The chat-like interface can be further developed into a user interface in which catalogers can upload large quantities of book titles and abstracts (such as an Excel spreadsheet) and obtain the associated FAST subject headings in batch.
Dr. Eric H. C. Chow is an independent consultant specializing in the application of Artificial Intelligence and Large Language Models for the GLAM (Galleries, Libraries, Archives, and Museums) sector in Asia and North America. He is also working as a part-time digital specialist at the Asia Art Archive, and a current member of the Big Data Study Lab (University of Hong Kong). Most recently, he served as the Digital Scholarship Manager at Hong Kong Baptist University Library, focusing on development of digital archives and digital humanities tools.
Sai Deng is the Metadata Librarian and Associate Librarian at the University of Central Florida Libraries. Her scholarly interests include digital libraries, metadata, linked data, research data, the application of AI in metadata, digital humanities, and Chinese Studies.
Lihong Zhu is the Head of Technical Services at Washington State University Libraries. Her research interests include Linked Data, Semantic Web, discovery interfaces, identity management, library management, artificial intelligence, Asian studies, and library office environment.

One thought on “Exploring the Future of Library Cataloging with AI and Multilingual Embeddings”