
In the first half of 2025, I had the opportunity to meet Frédérick Madore, a Canadian historian who was then invited by the École des Hautes Etudes en Sciences Sociales (EHESS) to the Condorcet Campus in Aubervilliers, France. During several seminars and conferences, he presented the impressive work he has been doing almost single-handedly since 2021: the Islam West Africa Collection (IWAC). The scientific aim of this data collection was primarily to compile a corpus of press articles, an under-used type of sources, for two research projects: 1-Youth and Women’s Islamic Activism in Côte d’Ivoire and Burkina Faso; 2- Muslim Minorities in Benin and Togo.

Fig. 1 : Homepage of the IWAC dtabase, https://islam.zmo.de/s/westafrica/page/home
This open-access database provides access to press clippings from the mainstream press in West African (Burkina Faso, Ivory Coast, Benin, Togo, Niger, Nigeria) as well as Islamic publications, and video recordings, all of those documents related to Islam. The period covered is from 1962 to the present day. There are currently around 14,000 items, mostly press articles (11,683) equivalent to 25 million words and 150 gigabytes of data! To take advantage of this collection, the result of a form of “digital hoarding” that has become familiar to many researchers around the world, it was necessary to use distant reading tools and AI.
The articles are therefore available directly on the website as well as organized through two thematic exhibitions created using Omeka S. It contains scanned documents or documents accessible online (on Wayback Machine), descriptive metadata, and texts acquired by OCR.
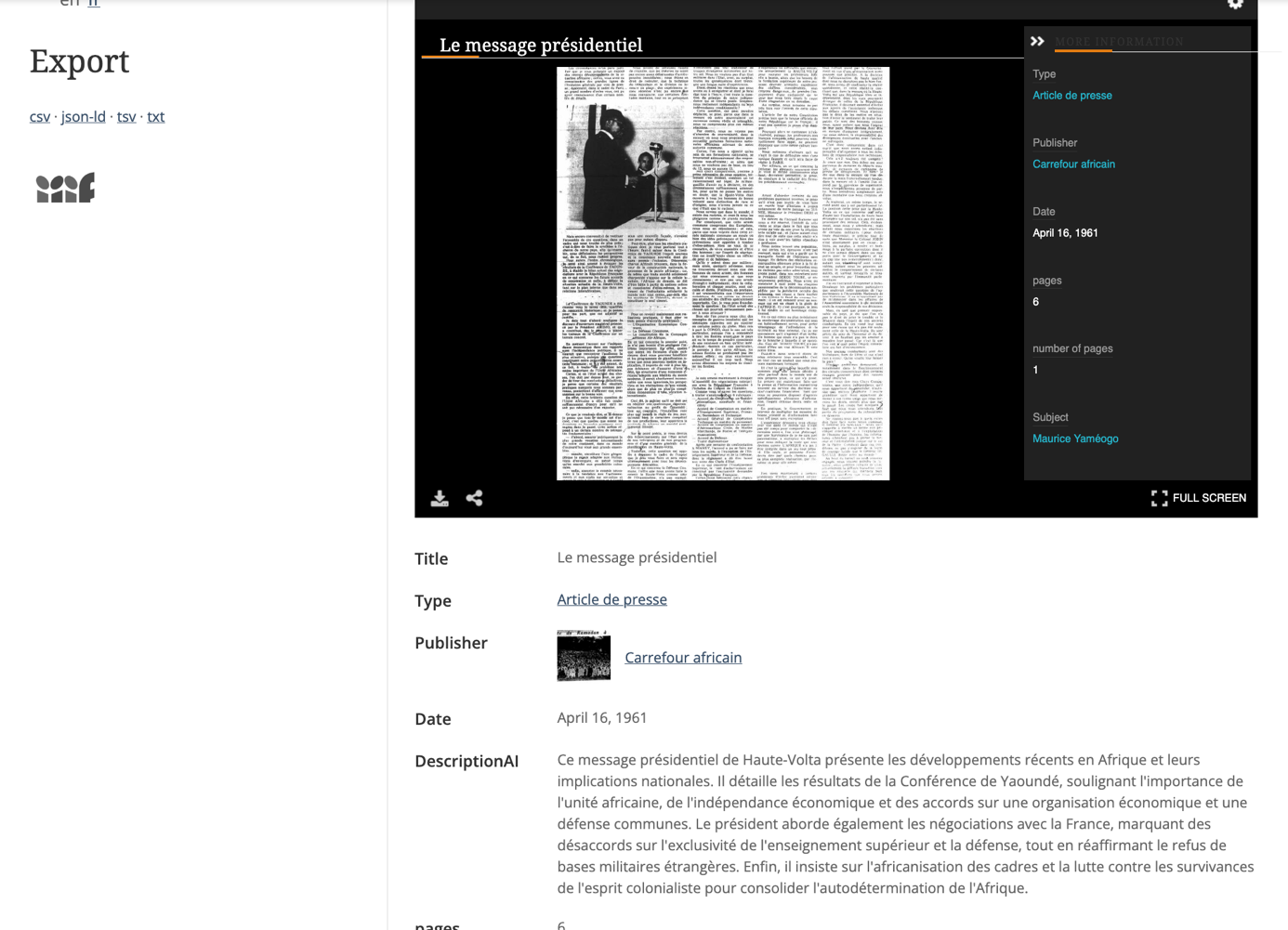
Fig. 2 : Example of an article available on the platform, with the metadata, export functionalities and below the full text engine searchable.
The data had to be prepared, i.e., written sources had to be converted into data (datafication). The articles were photographed in the numerous libraries and archives frequented by the author since his doctoral work, and scanned or photographed on site. They were then OCRed with an acceptable error rate, first with free software. Then F. Madore started experimenting with Python-based pipelines integrating LLMs to streamline document processing to improve OCR and enhance named entity recognition (NER) for metadata attribution. Finally, each article was given a simple set of descriptive metadata (following the principles of Linked Open Data) and a summary generated by AI. The corpus, which is mainly in French, can be searched using search engines and numerous faceting options.
This database goes even further and offers a multitude of tools.
The analysis tools provided go well beyond the already sophisticated navigation features. Complex tools enable discourse analysis and answer various scientific questions. They can be accessed via the ’Digital Humanities’ tab in the menu.
There is a keyword mapping, based on the 10 most frequently used keywords, which is presented on the site alongside one of Frédérick Madore’s research questions, namely the thematic developments in the way issues relating to Islam have been presented since independence. This reveals for instance a radical change in vocabulary since 2017, with the terms “terrorism” and “radicalization” becoming prevalent in journalists’ writing.
More complex, the “topic modeling” tab offers a sophisticated approach to querying datasets. Not being a specialist in discourse analysis, I find it a little confusing, but the tools and Python code are provided, so developers are free to use them.
The next tool is sentiment analysis, performed by two AI systems (Chat GPT and Gemini, to choose from). It is hosted on the author’s GitHub and accessible directly from the platform. Again, I leave it up to readers to explore it and query the data.

Fig. 3 : Explanation and tools for launching sentiment analysis on the corpus. https://islam.zmo.de/s/westafrica/page/sentiment-analysis
Spatial visualization offers heat maps, by country, based on mentions of places in national newspapers. While the maps are provided, their analysis is not included, and it is up to each user to decide whether or not to use them.
On the one hand, it is a database providing access to material that is difficult to access and highly specific, which can be reused by others and addressed with other research questions. But it is also an exemplary project that can inspire researchers to use the open access tools available to create their own platforms for analyzing and sharing their data.
The care taken to comply with open access best practices is truly admirable. Data can be exported in several formats and accessed in a viewer using the IIIF protocol. In addition, the site features an impressive research bibliography, with each reference receiving a reference in Wikidata as part of this project.
I would like to emphasize that this work was carried out almost entirely alone, without significant funding (except in 2023 from the Berlin Senate Department for Science, Health and Care), and was driven by the determination, perseverance, and clear vision of its author regarding the resources to be deployed and the expected outcomes of his project.
The precariousness associated with the non-institutional aspect should also be emphasized and has led F. Madore to find various answers to protect this work from disappearance. A postdoctoral contract in Berlin at the ZMO made it possible to host the database on the institution’s servers, and the data will be stored on the ZMO institutional repository. The downloadable dataset with the metadata is also available on Hugging Face.
The next step is a deep reflection on the use of AI in Digital Humanities and African Studies, to be followed!
2 thoughts on “Islam West Africa Collection: Dataset, Distant Reading, and Uses of AI for Discourse Analysis”