
This is the first part of a contribution based on a presentation given at The Digital Orientalist’s Virtual Conference 2025 (AI and the Digital Humanities) by Ziyi Qin (Beijing Foreign Studies University). The recording of the presentation can be found here.
Part 1 of the contribution explores data and methods. Part 2 explores the findings.
The extensive application of digital methods has opened new perspectives and paradigms for the study of Chinese classical poetry. This study focuses on two representative and influential poets of the Middle Tang period 中唐時期, Yuan Zhen 元稹 and Bai Juyi 白居易. Through computational analysis, it compares the spatial and temporal distribution of sentiments and examines their relationship with imagery in their poetry.
1. Data
1.1 Poems
The corpus used in this study is the Detailed Poetry Corpus of Yuan Zhen and Bai Juyi, developed by a research group I led. It contains 880 poems by Yuan Zhen and 2918 poems by Bai Juyi, each accompanied by rich metadata. A sample of the data structure is shown in Figure 1. The present study makes use of four fields: title, time, location and content.

Figure 1. Sample data structure of the corpus.
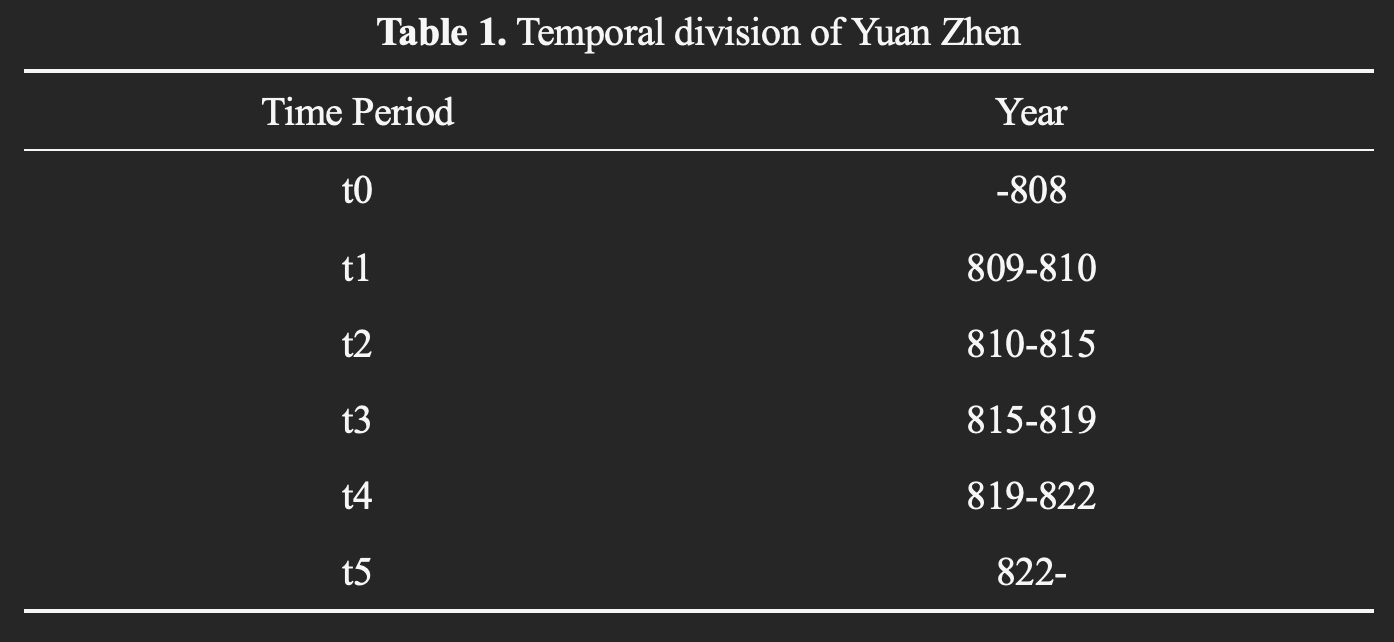
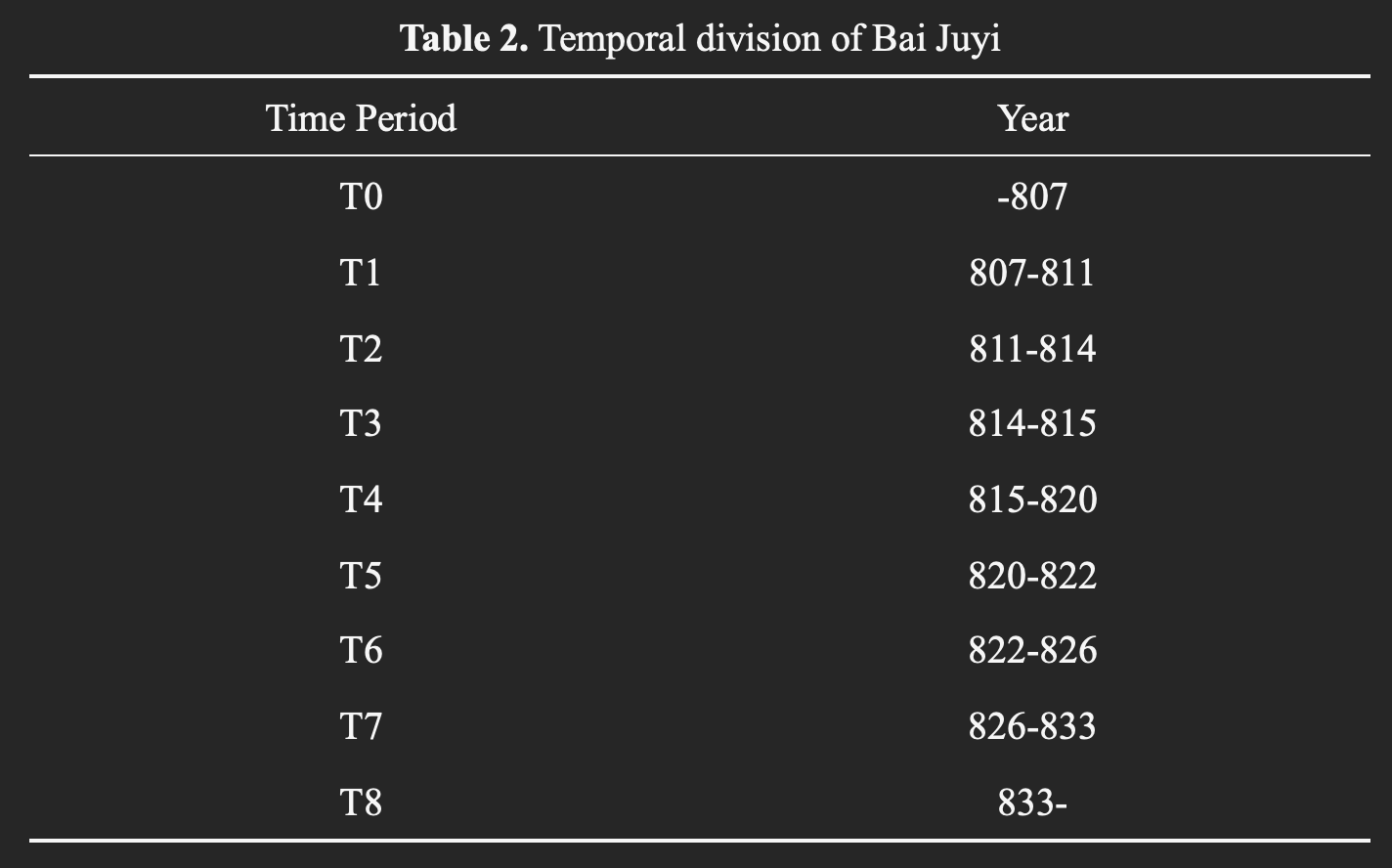
1.2 Temporal Division
To facilitate quantitative analysis, several time periods are defined based on major life events of each poet, as shown in Tables 1 and 2. Poems are then assigned to these periods according to their temporal information in the corpus.
1.3 Sentiment and Negation Lexicons
Building on the sentiment lexicon developed by Zhang et al. (2023, 2325–2346), this study makes substantial revisions by removing and adding words, and further refines the sentiment categories. The resulting lexicon comprises 293 sentiment words, organized into three primary categories and sixteen subcategories. Selected examples are presented in Table 3.

Additionally, a negation lexicon consisting of 23 words is constructed.
2. Method
2.1 Sentiment Word Matching
A bidirectional maximum matching algorithm is employed to identify sentiment words in the corpus. Given the common polysemy in Chinese, manual verification is conducted to ensure matching accuracy.
2.2 Handling Negation
Negation words occurring before or after sentiment words are collected to capture different negation patterns. A context window is defined around each sentiment word to identify nearby negation words and reverse the sentiment polarity. The correspondence between the original and converted sentiment categories is shown in Table 4. Since the original 16 sentiment categories do not include direct opposites for Tiredness and Arrogance, two new categories, Tiredness_re and Arrogance_re, are introduced.

This article continues in Part 2.

One thought on “Comparing Sentiments in Yuan Zhen’s and Bai Juyi’s Poetry: A Computational Analysis Across Time and Space (Part 1)”