
As artificial intelligence (AI) tools become ubiquitous in our society, AI functions are more accessible and visible. When you use your email, search for an academic work, or you receive a very long message, most websites and applications have an AI summarization tool immediately available for use. Emails, books, articles, and even text messages can now be summarized into smaller, bite-sized texts with just one click. As AI summarization becomes more common, it is important to consider how these tools work and any ethical issues that they pose. In this article, I will test the effectiveness of three AI summarization tools with a section of the Milindapañha, a Buddhist text, to see what elements are included and omitted.
Before this, however, it is important to understand what summarization was like before AI tools. Summarization is the reduction of a larger text or work into a short, clear description of its essential elements. The operative word here is “essential” because the key elements of a work are determined by the summarizer. Previously, human summarizers were expected to have a working knowledge of the work that they are summarizing so that they would produce a faithful description of the summarized work. Due to the reduction of size, it is impossible to include all elements of a work in a summary. So, some elements of the original work will be omitted in the summary. When a reader reads a summary and does not read the original work, they have faith that the summarizer included all of the essential elements.
AI text summarization on the other hand primarily comes in two forms: extractive and abstractive. Both types of AI summarization extract text from the original document and use natural language processing (NLP) and reasoning models to process the text prior to generating an output. The key difference is in the style of output. Extractive summarization statistically identifies sentences in a text that are important, while abstractive summarization generates new text that aims to summarize the main points of the input text. The output text consists of as much as 50%, to as low as 10% of the original text depending on the model. In either case, the summarized output is generated according to the model’s neural network, which is built from its training data and biases
Due to their complexity, it is extremely difficult for us as humans to understand exactly how the internal system of an LLM reaches specific responses in its outputs. However, we do know that all outputs are based on and limited by their training data. The composition of AI training data for most models is not publicly available, but several studies of AI-generated outputs have been published. For example, a recent study by Tao et al. found that GPT models, specifically GPT-3, 3.5-turbo, 4, 4-turbo, and 4o, tended to generate outputs that were quite similar to the integrated values of western European countries (Figure 1).
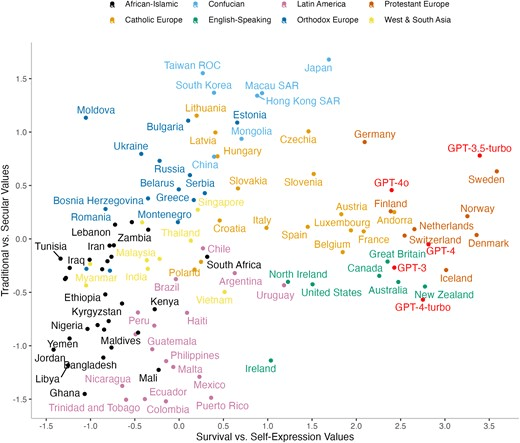
Figure 1: A distribution of 107 countries/territories based on Integrated Values Surveys by Inglehart and Welzel 2005. On the x-axis, negative values represent survival values and positive values represent self-expression values. On the y-axis, negative values represent traditional values and positive values represent secular values. Five LLMs (in red) are mapped according to their responses to the same questions. Image from Tao et al., “Cultural bias and cultural alignment of large language models”, 2024. Available at: https://doi.org/10.1093/pnasnexus/pgae346. ©Tao et al.
This suggests that these models would summarise texts from a similar culture traditions more accurately, but what happens when they summarise texts from cultural traditions with significantly different integrated values? The essential and important elements of a text from a South Asian tradition might not match with the forms expected by western European traditions, and as I found, this leads to omission, misinterpretation and misunderstanding of important South Asian elements of a text.
Omission of Sensitive Content
In addition, most GenAI tools have built-in content restrictions that prevent the tools from generating outputs that include restricted themes or elements. For example, Google restricts Gemini from generating content related to dangerous activities, threats to child safety, violence and gore, harmful factual inaccuracies, sexually explicit material, harassment, incitement, and discrimination. In practice, GenAI model will respond to an input requesting restricted content in three different ways. The most common response is an output indicating that the request breaches content restrictions, so the model is unable to complete the request. This restriction can sometimes be circumvented by adjusting the input to mask some of the restricted elements of the request. However, the more problematic issue lies in requesting outputs about things with some restricted elements associated with them.
For example, when prompted to write poems about two different Ancient Greek sex workers, porna and hetaira, Claude 3.5 Sonnet responds in two different ways (Figure 2).

Figure 2: Left: Anthropic, Claude 3.5 Sonnet, 10 September 2024 version, personal communication, generated by Edward A. S. Ross on 27 September 2024. Prompt: ‘Write a poem in Latin about a porne.’ Right: Anthropic, Claude 3.5 Sonnet, 10 September 2024 version, personal communication, generated by Edward A. S. Ross on 27 September 2024. Prompt: ‘Write a poem in Ancient Greek about an hetaira.’ Image from Ross et al., “Taking the Helm: Collaborative Approaches to Ethical AI Practice in Ancient Language Learning”, Digital Culture & Education. ©Ross et al.
In response to the porna prompt on the left, Claude declines to generate a text which includes explicit sexual content or pornographic themes due to its content restrictions, but it does not indicate why a porna would be associated with this type of content. On the right, in response to the hetaira prompt, Claude does generate a poem, but it only alludes to a hetaira’s role as an entertainer. It makes no reference to their role as sex workers in the Ancient Greek context. If a user is unaware of this expanded context, they could easily overlook the sexually explicit aspect of this profession, sanitizing their understanding of the ancient world.
Considering the cultural context of GenAI tools and their content restrictions, it is important to assess what is included in summarization, but more crucially, what is omitted from these summaries. Not everything can be included in a summary, but certain elements or themes might frequently be omitted. In order to test this, I will be comparing the outputs of ChatGPT 5.1, Claude 4.5 Sonnet, and M365 Copilot through their summaries of Book 1 of the Milindapañha.
The Milindapañha is a Buddhist text that describes an account of a Greek king, Milinda, engaging in debate with a Buddhist monk, Nagasena. The text appears in both the Pali and Chinese Buddhist canons, but I will be focusing on the Pali version for this test. The Pali Milindapañha is divided into 7 sections: the first introducing the events prior to the debate, and the remaining six each describe one portion of the philosophical debate. I will be using the first section for this test as it is primarily a narrative rather than philosophical discussion. Because it is important to not upload any copyrighted content into an AI model, I will be using the 1890 English translation by T. W. Rhys-Davids.
Since it is very difficult to guarantee that any data used in a GenAI input will not be used for further AI training, it is crucial that only open access data is inputted when using popular GenAI models. Furthermore, this open access data should only be used if the materials are permitted for use in GenAI. Following these principles, I will only be using the version of the Milindapanha Rhys-Davids translation maintained on Wisdom Library for these tests. Bearing these ethical concerns in mind, I can now discuss the three AI summarization tests I conducted.
ChatGPT 5.1 Summarization
ChatGPT 5.1 was the first model I tested, and it quickly generated a summary of the Milindapañha section with direct, repeated links to the specific page I restricted it to in the input (Figure 3).

Figure 3: OpenAI, ChatGPT 5.1, 12 November 2025 version, personal communication, generated on 15 November 2025 by Edward A. S. Ross. Prompt: “Summarize Book 1 of the Milindapanha found here: https://www.wisdomlib.org/buddhism/book/milindapanha-questions-of-king-milinda/d/doc1460769.html .”
This summary follows a bullet point style and breaks the text into thematic sections. It describes several themes and details present in the narrative, connecting them to the future discussions in the later sections. The included citations for each line, however, simply links to the top of the page rather than to specific sections of the text, making it difficult to clearly identify which part each point discusses. The summary also omits a significant portion of the previous history text. In particular, the past-life connection between Milinda and Nagasena. This karmic connection between the figures is a frequently-occurring pattern in Buddhist texts, so removing it omits important Buddhist narrative elements from the description of the text.
Claude 4.5 Sonnet Summarization
The Claude 4.5 Sonnet output in response to the same input prompt is more abstractive than ChatGPT 5.1, using short paragraph summaries for each section rather than bullet points (Figure 4).

Figure 4: Anthropic, Claude 4.5 Sonnet, 23 October 2025 version, personal communication, generated on 15 November 2025 by Edward A. S. Ross. Prompt: “Summarize Book 1 of the Milindapanha found here: https://www.wisdomlib.org/buddhism/book/milindapanha-questions-of-king-milinda/d/doc1460769.html.”
In this instance, the summary includes four selected narratives from the overall chapter and reduces their content into short descriptions. Some personal names and numerical figures are mentioned, but many are excluded. The term Abhidhamma (technical commentaries on Buddhist doctrine) is also glossed imprecisely as “Buddhist philosophy.” Once again, direct links to the top of the Wisdom Library page are used as citations, obscuring the specific sections used in the summary. This truly defeats the purpose of the citation because a user would need to read the full text to determine which section the summarized line references.
M365 Copilot Summarization
M365 Copilot’s output follows a similar structure to ChatGPT 5.1’s in that it uses bullet points to summarize the text, but Copilot goes a step beyond the input prompt request and contextualizes the source as well (Figure 5).

Figure 5: Microsoft, M365 Copilot, 12 November 2025 version, personal communication, generated on 15 November 2025 by Edward A. S. Ross. Prompt: “Summarize Book 1 of the Milindapanha found here: https://www.wisdomlib.org/buddhism/book/milindapanha-questions-of-king-milinda/d/doc1460769.html.”
Although the context is helpful here, it leads the model to omit significant portions of the narrative in Book 1. At most, the Copilot summarization identifies the main two characters, Milinda and Nagasena, and includes one of the major city settings, Sagala. The remaining points largely focus on the literary purpose and context of Book 1 rather than its content. Furthermore, this expanded remit of the output likely also explains the 13 additional sources included in the citation list for the summary, including Wikipedia, Access to Insight, and Buddhist E-Library. Some of these cited sources, including Learn Religions, indicate in their terms of service that their content should not be used to train AI models, an issue which my choice of Wisdom Library as the sole source aimed to avoid. M365 Copilot not only omitted most of the narrative of Book 1 but also included unrequested, external content to create a summary.
Common Findings
One particular omission from all three summaries is the female follower mentioned in section 30 of this chapter. Although she is not named, she is the only female character in the full text to participate in narrative actively, rather than appearing as a philosophical example. She is also the only female character that appears in this chapter on her own rather than in a grouping, so it is odd that her unique presence is not mentioned in the summaries.
To see if a model could identify if any features were missing from its own output, I converted the M365 Copilot output in Figure 5 into a pdf and prompted Copilot to compare the pdf summary to the Wisdom Library text, indicating all important things that were omitted (Figure 6).

Figure 6: Microsoft, M365 Copilot, 27 January 2026 version, personal communication, generated on 30 January 2026 by Edward A. S. Ross. Prompt: “This is a summary of Book 1 of the Milindapanha found here: https://www.wisdomlib.org/buddhism/book/milindapanha-questions-of-king-milinda/d/doc1460769.html. Compare the pdf to the original website text and list all important things that were omitted.”
The critique highlights how the majority of the narrative, characters, and descriptions are omitted from the initial summary, so it is able to identify some important elements of the text. The model concludes that the inputted summary “captures the theme but omits almost all narrative substance,” which is accurate. However, the female follower from section 30 is once again omitted from the critique. Although not a central character, her frequent omission highlights the significant risk for the perpetual omission of certain thematic or cultural elements from GenAI summaries.
Concluding Thoughts
With the frequency of AI-generated summaries appearing across the digital world, people are now putting faith in AI tools to determine what elements of a work are essential. If we treat these AI-generated summaries the same as human-generated summaries, this poses significant risks related to accuracy and the preservation of history. It is crucial that we critically examine all AI outputs and do not take AI summarizations at face value. Otherwise, we risk a persistent loss of information and cultural context. Furthermore, if the original texts are ever accidentally lost, AI summarization errors may eventually lead to a permanent loss of this information and cultural context in the not-so-distant future.
Cover Image: Microsoft, M365 Copilot, 12 November 2025 version, personal communication, generated on 15 November 2025 by Edward A. S. Ross. Prompt: “Create an image of the Milindapanha.”
References
Anthropic. Claude 4.5 Sonnet (23 October 2025 version) [Large language model]. 2025. https://claude.ai/new.
Buddha Dharma Education Association, and BuddhaNet. “Milindapanha.” Buddhist E-Library, 2009. Accessed 31 January 2026. https://www.buddhistelibrary.org/buddhism-online/dharmadata/fdd66.htm.
Google. “Policy guidelines for the Gemini app.” Gemini. Accessed 27 January 2026. https://gemini.google/policy-guidelines/.
Kelly, John, trans. “Milindapañha: The Questions of King Milinda.” Access to Insight (BCBS Edition), 24 November 2013. Accessed 31 January 2026. https://www.accesstoinsight.org/tipitaka/kn/miln/miln.intro.kell.html.
Microsoft. M365 Copilot (12 November 2025 version) [Large language model]. 2025. https://www.microsoft.com/en-gb/microsoft-365-copilot.
Murel, Jacob, and Kavlakoglu, Eda. “What is text summarization?” IBM, 6 May 2024. Accessed 13 November 2025. https://www.ibm.com/think/topics/text-summarization.
O’Brien, Barbara. “King Milinda’s Questions and the Chariot Simile.” Learn Religions, 25 June 2019. Accessed 31 January 2026. https://www.learnreligions.com/king-milindas-questions-450052.
OpenAI. ChatGPT 5.1 (12 November 2025 version) [Large language model]. 2025. https://chatgpt.com/.
People Inc. “Terms of Service.” People Inc., 31 July 2025. Accessed 31 January 2026. https://www.people.inc/brands-termsofservice?_gl=1*1tb50s8*_ga*MTM2ODM3MDY4OS4xNzcwMDcxMTIz*_ga_DK3GDWHWJH*czE3NzAwNzExMjMkbzEkZzEkdDE3NzAwNzExMzkkajQ0JGwwJGgw.
Rhys-Davids, T. W., trans. (1890). Milindapanha: The Questions of King Milinda. Sacred Books of the East XXXV & XXXVI. Oxford: On the Clarendon Press.
Ross, E. A. S., Baines, J., Hunter, J., McRitchie Pratt, F., and Patel, N. (forthcoming). “Taking the Helm: Collaborative Approaches to Ethical AI Practice in Ancient Language Learning,” to be published in Digital Culture & Education.
Tao, Yan, Viberg, Olga, Baker, Ryan S., and Kizilcec, René F. “Cultural bias and cultural alignment of large language models.” PNAS Nexus 3(9) (2024): 1-9. https://doi.org/10.1093/pnasnexus/pgae346.
von Hinüber, Oskar. (1996). A Handbook of Pāli Literature. Indian Philology and South Asian Studies 2. Berlin: Walter de Gruyter.
Wikimedia Foundation. “Milinda Panha.” Last modified 17 December 2025 at 06:20 (UTC). https://en.wikipedia.org/wiki/Milinda_Panha.
Wisdom Library. “Milindapanha (questions of King Milinda) – Book 1 – The Secular Narrative.” Wisdom Library, 10 October 2024. Accessed 12 November 2025. https://www.wisdomlib.org/buddhism/book/milindapanha-questions-of-king-milinda/d/doc1460769.html.