
During last spring I thought a lot about the topic for this post. I even felt a certain discouragement, which was caused – I believe – by a crucial question I asked myself. I wondered what are the main reasons that make me choose to explore one topic over another, and what is the relationship between these reasons and the aims I am pursuing. Below I will try to explain these doubts, before moving on to the topic I realized (not ‘decided’) I wanted to talk about.
First, I thought back to one of my debut contributions (‘Back to the Sources’: The First Steps in (Digital) Projects) for the Digital Orientalist, in which I had explained the workflow of an ongoing digital project related to an actual and concrete research object of mine, and then I went back to my second post (Codicological Visualization of a Syriac Manuscript with Viscodex), which was of a more practical type, where I presented an experiment done with a derivative instrument (VisCodex) of the VisColl data model. In the latter I defined the topic in a completely fictitious way for didactic purposes only. These two writing experiences differ from each other, and their simple contemplation led me to formulate the following, somewhat apodictic, conclusions:
- First, I don’t like to use some digital tool just for the sake of using it.
- Second, I don’t even like the very idea of using some digital tool just for the sake of it.
On this basis, I think it clearly emerges how much hunting for what I would call a “research pretext,” in order to show the use of this or that digital tool, repulses me. So, having quickly realized at least what I did not want to do, I then put the initial question aside, and happily went back to my research (see the above mentioned related post) on Jacob of Serugh’s cycle of five ‘Homilies on the spectacles (of the theatre)’.
In this cycle of texts, as I have recently noticed, the author’s interest in the figure of the prophet Moses reaches far beyond those places that are reproduced in the extracts provided by the 1935 edition. Since the widely recognized feature of intertextuality in Jacob of Serugh’s works clearly emerges also in the collected texts ‘On the theater’, I tried to get an idea of other homilies he composed. Among these homilies (there are around a dozen, if my count is right) few have been edited and/or translated. One version can be found in Bedjan’s edition[1] and the title of this work is taken from MS Vat. Syr. 114, is ܡܐܡܪܐ ܕܥܠ ܫܘܫܦܐ ܕܒܐܦܝ ܡܘܫܐ (“Homily on the veil upon Moses’ face”). There were good reasons to believe this text might contain references to the theatre material world or even to the theatre as an artistic genre. Either way, I had some urgency to read the text in translation in order to grasp at a glance the main themes and tropes it contains without being sidetracked by the usual problems arising when translating on your own from scratch. I would like to point out that two translations in European languages exist, one[2] in English and the other[3] in French (the latter has been kindly provided to me lately by a collegue via the Hugoye mailing list). Due to various reasons, initially (when I began to gather materials on that specific homily), I could not access any of them.

Fig. 1 Homiliae Selectae Mar-Jacobi Sarugensis (ed. Bedjan, 1907, vol 3).
Very soon into my search, and with a feeling of déjà-vu, I remembered also the existence of a German edition, whose title, unfortunately, I could not remember. After a quick check on syri.ac, an invaluable annotated bibliography of open access resources for Syriac Studies, I found the edition (here)[4], and I discovered the reason for my recollection: I had already searched and found that German translation in the past!

Fig. 2 Homilie über die Decke vor dem Antlitze Moysis (ed. Bickell, 1874).
This text is printed in the most common typeface of that period, the so-called “Fraktur” (it is a form of Blackletter, also known as Gothic script), which is rather difficult to read for an untrained eye. Having retraced my steps twice already and facing again the same obstacles, this time, I decided not to skip it, especially since I had, incidentally, found the right subject for my post.
The first step in making rabbit stew is catching the rabbit
Isaac Asimov
Therefore, in order to obtain, in a non-cyclopic time, the transcription of the 16 pages of this 19th century translation into a typeface more easily readable for me, so as to satisfy my eager desire to read the homily ‘On the veil upon Moses’ face’, I decided to turn to the Transkribus platform. I am familiar with Transkribus since I participated in a two-part digital workshop led by Dr. C. A. (Annemieke) Romein[5] (Huygens ING – KNAW) together with Johanna Walcher (READ-COOP) during the spring of 2020. From that exhaustive workshop two video tutorials were produced, which I include links for below (there are many also how-to-guides on Transkribus’s website):
Transkribus is a paid platform intended -as declared- “for the digitisation, AI-powered text recognition, transcription and searching of historical documents.” It uses a credits system and every user receives 500 free credits on sign-up. I noticed that exists also a Transkribus Scholarship Programme which allow students and teachers to apply for a scholarship to get free credit packages for their thesis projects or for their courses etc. The Graphic User Interface (GUI) of this tool is undeniably quite user-friendly. For doing the present, automated, transcription work, I used the desktop version of Transkribus. The lightweight version of it (Transkribus Lite) that can be used in your browser has, on the other hand, some reduced features, but is enough to perform manual transcriptions (and even to set up collaborative ones).
Within the Transkribus platform, there are around 60 trained models for the text recognition (OCR/HTR) of specific languages that have been made publicly available. There are, however, few languages and/or scripts (the same script can be used in different languages) that might interest a more typical reader of the Digital Orientalist. For instance, whilst the ‘Arabic alphabet’ is listed as searchable among the scripts, a public model for the Arabic language is not yet available. As far as I know, several experiments on Arabic texts have so far been performed with this instrument, such as those within the project focused on scientific manuscripts that is reported on here.
As for Ottoman Turkish, there are many non public model(s) trained with Transkribus, some of which are in the process of being refined, such as, for example, those by the project on Digital Ottoman Studies platform that is reported on here[6]. In addition, a network (The Ottoman Text Recognition Network) which aims to bring together researchers and students interested in the topic was also set up this year. Models for the following languages are currently publicily available: the HTR model for Classical Ethiopic, trained as part of the Beta maṣāḥǝft project, two models for languages using the Devanagari script (Sanskrit, Hindi, Marathi, Kashmiri, Sindhi, Nepali), and a model for Hebrew-script languages (Hebrew, Yiddish, Ladino and Judeo-Arabic).
For Syriac handwritten texts three models are available, trained by the Beth Mardutho Syriac Institute team members for Serto, Estrangelo and East Syriac scripts (see Beth Mardutho Quroyo project):
- ‘Beth Mardutho Qoruyo Serto 1.0’ model
- ‘Beth Mardutho Qoruyo Syriac
–Estrangelo 1.0’ model - ‘Beth Mardutho Qoruyo East Syriac 1.0’ model
Among these, the model for Estrangelo is the one that has thus far reached the best and most significant results for accuracy (it has a ‘Character Error Rate‘ (CER) of 2.98% on its Validation Set). The HTR models for Syriac are not yet public, but you can ask permission to use them sending ane mail to Beth Mardutho.
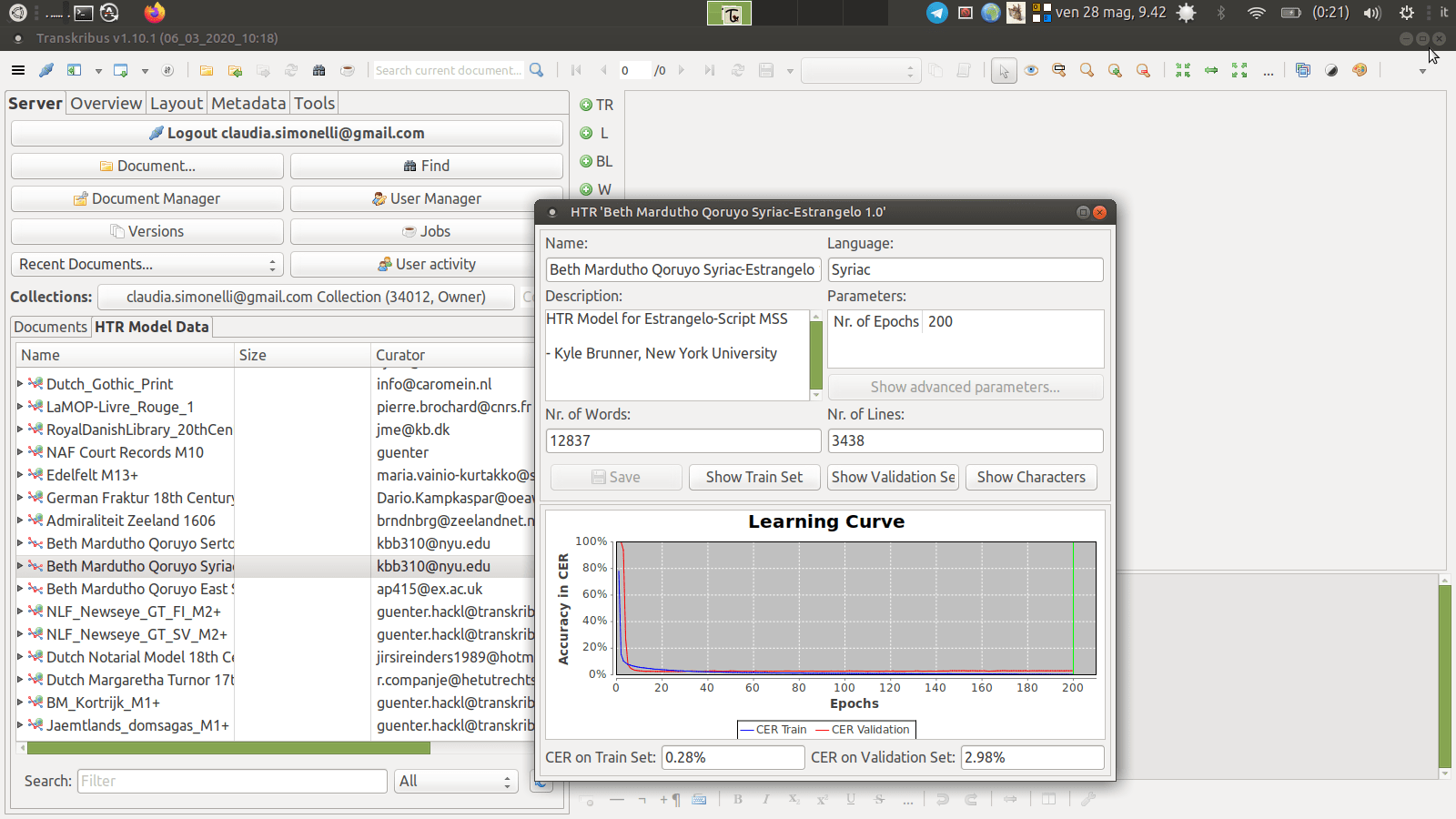
Fig. 4 Learning Curve graph of ‘Quroyo Syriac-Estrangelo 1.0’ model.
Turning back to German, on which I focused for work on the Bickell edition, several models for that language are available in Transkribus. To pick one, I first looked at the language concerned, the print date and the script used, flagging in the query box the following options:
- Language>German
- Century>19th
- Script>Gothic Script
The query returned three models, each one of them I marked (Fig. 5), in their given order, with a Syriac letter. Then, to verify which of the models was the best fit for my source material I compared them empirically, not based upon their CER (it could have been an option) but on the visual collation of some images from the respective Training Sets. On the basis of this analysis, I opted for the ‘NZZ Gold Standard M1+’ model which I marked with the letter ‘beth‘ ܒ. This model had been trained on title pages from the Neue Zürcher Zeitung (NZZ) covering the years 1780-1940.
Fig. 5 Scores entries of Transkribus’ models for the German Fraktur script.
The overall work to get the transcription done -from the building of the images dataset (I downloaded the complete book from the Internet Archive as ‘.zip file of single processed pages’, so I had the images directly in the TIF format, one of those allowed by Transkribus) to the automatically performed Layout Analysis (I then manually refined it by correcting minimal things as for the segmentation of the text, since the engine in its standard setting recognized as part of an single Text Region, for example, the decoration under the title and the running titles of the pages), then to the final output- took just over an hour. Which is not that bad at all, if considering that I also did a session to test the functioning of the model on couple of pages before proceding on the whole set of images. To that, we must add another half an hour for the comparison of the trancription with the source text.
The transcribed text produced an almost perfect (the model I chose has, after all, an accuracy rate of 99.52%), with some few exceptions. The tool has, only once, wrongly segmentated the text splitting a line into two, producing blank space. It also “iper-correctly” transcribed an error due to print (that is to say, a point mark where the Bickell edition shows a not well-printed comma). The word ‘Homilie’, referring to the title of the text genre, has been recognized as Homili/s/ (Fig. 6), while the name ‘Moysis’ has been replaced, just in one place, with Mo/y/sis, and some of the footnotes reference numbers rendered as ! ) or : ) instead of 1 ), and ? ) instead of 2 ).
Fig. 6 Example of a recognition/transcription error.
In this way, thanks to a digital tool which -it must be stated- I already had acquired the skills to use, I could build for myself a tiny digitised resource (from an analogical/digitized source) in a relatively small amount of time. I made the German translation of the text of Jacob of Serugh’s ‘Homily on the veil upon Moses’ face’, as automatically transcribed via Transkribus and from there exported in TXT format, available here.
Moreover, I can say the hunt has paid off since, along with other metaphors and similies throughout the text, in the very first lines of the proemium[8] one finds the Syriac author wondering, through the device of questions a wise man poses to him, what reason Moses, a man who had spoken with God, had for standing, veiled, in the midst of the great people of the Hebrews “like a spectacle” (Bickell’s transl.: “wie ein Schauspiel”; Mouterde’s transl.: “tenir […] le rôle d’un masque de théâtre”; syr. text: ‘(pl.) ܐܝܟ ܕܚܙܘ̈ܢܐ’).
Even though I did this automated work to gain more insight into a “mere” secondary source, I think I can consider it a good achievement and, speaking in a more general way, also good evidence of the fact that, as in traditional studies, even in those with digital aspects, one does not risk wasting time if one first spends time trying to find good research questions to strive to answer.
Cover image: Albrecht Dürer, Young Hare, 1502 (©The ALBERTINA Museum, Vienna). Public domain, via Wikimedia Commons.
References
[1] Homiliae Selectae Mar-Jacobi Sarugensis, ed. Bedjan, vol. 3 (Paris/Leipzig: Harrassowitz, 1907): 283-305 (n. 79). Bedjan declared (p. vii of Preface) he used MS Vat. Syr. 114 (6th c., ff. 46r-50v) and MS Vat. Syr. 117 (12/13th c., ff. 23r-25v). In the Biblioteca Apostolica Vaticana the text of the homily ‘On the veil’ is transmitted also in MS Vat. Syr. 252 (before 932 CE, ff. 37rb-40rb), which appears badly damaged.
[2] Sebastian P. Brock, Jacob of Sarug’s Homily on the Veil on Moses’ Face: Translation and Introduction, Texts from Christian Late Antiquity 20: The Metrical Homilies of Mar Jacob of Sarug, Fascicle 1 (Piscataway, NJ: Gorgias Press, 2009).
[3] Paul Mouterde, “Homélie sur le voile du visage de Moïse”, Dieu Vivant 12 (1948): 49-62.
[4] Gustav Bickell, Ausgewählte Schriften der syrischen Kirchenväter: Aphraates, Rabulas und Isaak v. Ninive, zum ersten Male aus dem Syrischen übersetzt, Bibliothek der Kirchenväter 30, (Kempten: Jos. Kösel, 1874): 259-274.
[5] Annemieke Romein (has a website) is a certified, though independent, trainer by Transkribus, and as an active user of Transkribus engaged herself in providing several workshops to aid users in their research.
[6] Suphan Kirmizialtin and David Joseph Wrisley, “Automated Transcription of Non-Latin Script Periodicals: A Case Study in the Ottoman Turkish Print Archive”, (2020).
[8] Homiliae Selectae Mar-Jacobi Sarugensis: 184.