
Following my first post for the Digital Orientalist on the topic of OpenRefine, in this post I would like to share more ideas about data cleaning of Chinese language-based materials with OpenRefine.
This post will use the Qing dynasty code of conduct “Yüfú zhì 輿服志” from Qīng shǐ gǎo 清史稿 for demonstration. A reliable digital version of Yüfú zhì can be obtained from the digital library Chinese Text Project (from Zhì qīshíqī 志七十七 to Zhì bāshí 志八十). As previously introduced, logging into the system allows the full text to be downloaded in plain text. Hence we can have the full text of Yüfú zhì stored in a txt file on the local computer. By using the method discussed in the previous post, punctuation can be removed with OpenRefine so that the text is all ready for analysis (for an alternative method see “Some thoughts on regular expressions” by Mariana Zorkina). However, this time we will explore some additional techniques provided by OpenRefine for more advanced treatment of the text.
Released by the Qing government and documented by later intellectuals, Yüfú zhì consists of a series of directives regarding attire and carriages that should be followed by people of each social stratum, from the emperor to commoners. The text mainly specifies rules that need to be obeyed, but occasionally it describes practices that are prohibited. Considering this feature of Yüfú zhì, a more accurate textual analysis can be pursued targeting on either the permissions or the prohibitions. With the help of OpenRefine, it is possible to select or filter out sentences that describe prohibitions by identifying certain keywords that are included in the sentences. In the pre-modern Chinese language, characters that indicate the prohibitions of actions usually include no (bù 不), forbid (jìn 禁), and stop (zhǐ 止), and thus by locating these keywords we will be able to identify sentences indicating prohibitive rules in Yüfú zhì.
Separating sentences is an essential step in this project so that we can treat each sentence individually. But before this step, it is important to understand that in the Chinese language sentences can end with one of three punctuation marks – period (。), question mark (?) and exclamation mark (!). The latter two punctuation marks can be easily replaced by period using “find and replace” function provided by any txt file editor. Then the preprocessed text can be uploaded to OpenRefine for treatment. To start, we create a line-based project for Yüfú zhì in OpenRefine (the method for this is described in the previous post). The created project should have the entire text displayed in one column (fig. 1).

Fig. 1 – The created project for Yüfú zhì.
We first remove all punctuation marks except for the periods to achieve a clean text (the method can be found in the previous post). Then, from the drop-down menu of “Column 1” we choose the “Split into several columns…” option under the “Edit column”. Type in your separator, which in this case is a Chinese period ” 。” (fig. 2).
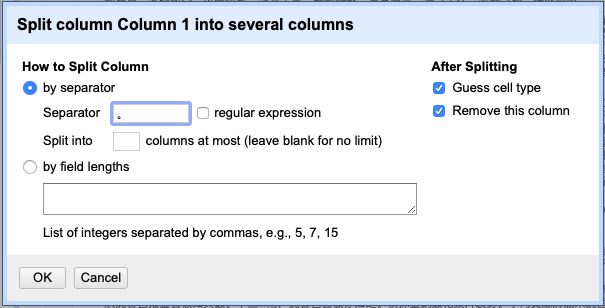
Fig. 2 – Separating sentences.
This step will result in a dramatic change of the view for your project – you will now have numerous small blocks spread out with each one consisting of an individual sentence (fig. 3).
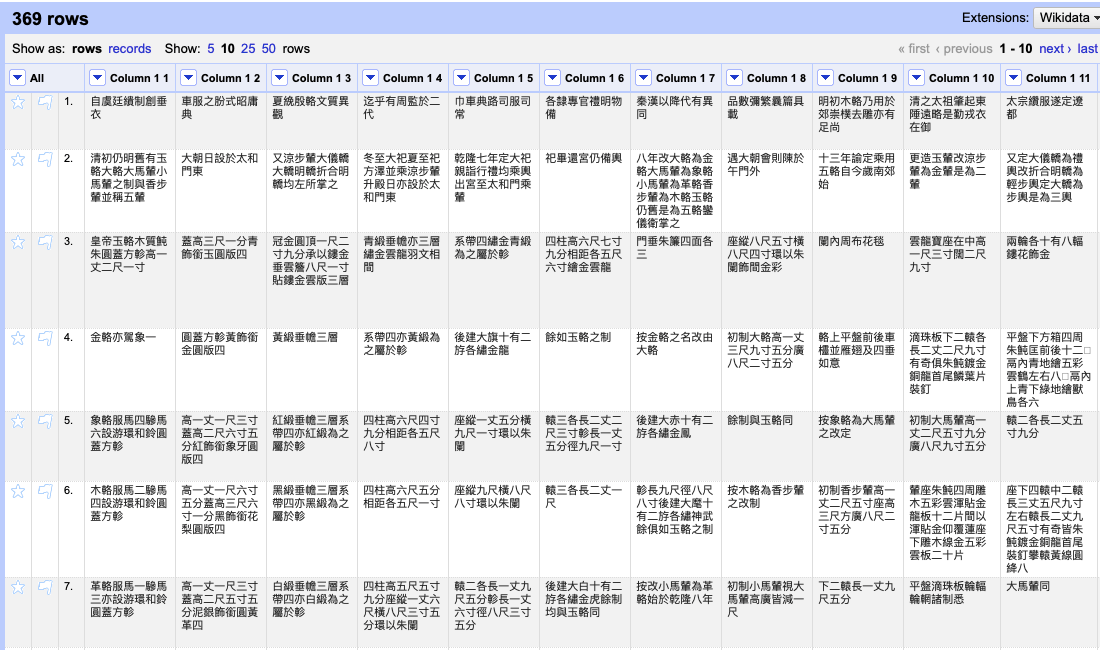
Fig. 3 – Columns split.
Now, the project is shaped in a format that has three advantages for potential text analysis. First, sentences remain complete and are independent from each other. Second, the text is free from the noise caused by any punctuation marks. Third, individual sentences that contain certain information can be further identified by locating keywords.
Filtering is the next task. It allows us to select or filter sentences that we do or do not wish to include in our project. It should be noted that OpenRefine functions like Excel in many ways, so it treats data in the same row as a unit. Therefore, to edit each sentence as an individual unit, we will need to transpose columns into rows. To do this, we select the “Transpose cells across columns into rows…” option under “Transpose” from the drop-down menu of any column. In the pop-up window we select all columns, and then choose “One column” and name it 輿服志 (fig. 4).
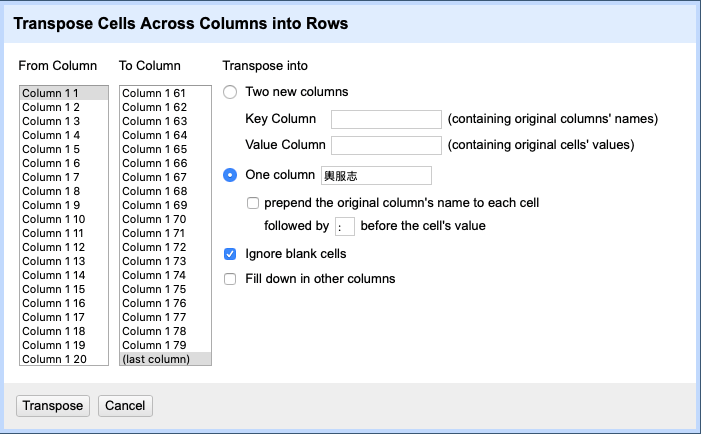
Fig. 4 – Transposing cells.
This operation will transform the layout of the project so that it displays only one sentence in a row. Now, filtering is easy to do. From the drop-down menu of the column, we click “Text filter,” and then in the left-hand side box we input any keyword. Clicking “invert” or not will allow the sentences to be included or excluded. In this example, we type in 不 and choose “invert” to display only sentences without the keyword 不. We then create two more text filter bars to exclude sentences that contain 禁 and 止. Now we can see that in a text with a total of 2718 rows 2633 do not include prohibitive keywords (fig. 5). The project is now ready to be exported for further text analysis. Likewise, unclicking “invert” gives a result of only prohibitions kept in the project.
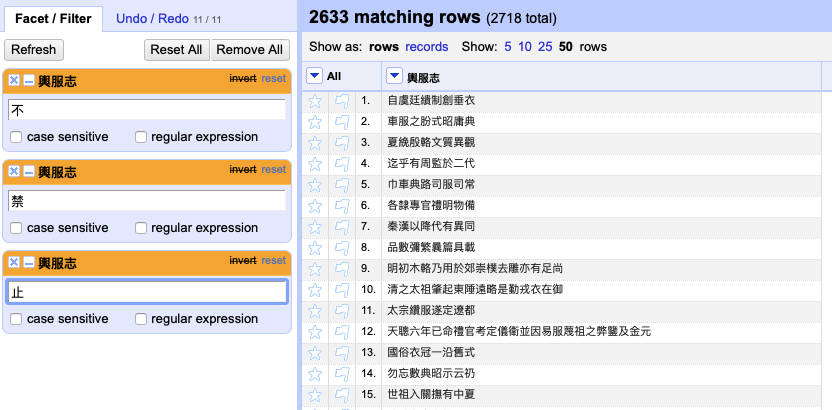
Fig. 5 – Sentences filtered.
In this post, I have discussed how to identify and filter sentences that contain certain keywords in Chinese-language based sources with OpenRefine. The purpose of this treatment is to narrow text analysis down to targeted data. In the demonstration, characters with prohibitive meaning were selected. Likewise, other indicators in Yüfú zhì are applicable as well, such as colours, measurements, and materials.
2 thoughts on “Data Cleaning Chinese Text with OpenRefine: Sentence Filtering”