
The “Text Encoding Initiative” (TEI) offers the most comprehensive guide to the computerized coding of texts in the humanities field today. “Its chief deliverable is a set of Guidelines which specify encoding methods for machine-readable texts, chiefly in the humanities, social sciences and linguistics.”1 Lou Burnard, in his book titled What Is The Text Encoding Initiative?, mentions the benefits of the TEI project for the humanities.2 Burnard mentions some specific advantages of TEI XML documents in the Introduction:
Meaning before format: You can make meaning-based queries to easily distinguish whether the word London in the text is in Canada or England, or whether it is a surname of a person.
Software independence: each computer has their own idiosyncratic ways of storing information. There can be changes in transfers from your PC to someone else’s Mac or Linux computer with loss of information. But the TEI XML document always looks the same.
Community-driven: TEI has combination of flexibility focusing on the scientific needs of a particular community. Thus, it can be constantly updated according to developing and changing needs.
Thanks to TEI, which was created in 1994, researchers have the ability to reveal thematic connections between words, and to analyze the meanings of words, not only their graphic structures. Computer software, which is mostly under the control of private companies and whose sustainability strategies depend on the private sectors, has structural differences. For this reason, electronically generated data may be subject to corruption or changes resulting from different software. However, a coded text can create a standard humanities coding template. TEI, which provides the thematic coding according to the needs of human researchers and their own conscious choices beyond the language of the software world, ensures the digitization and protection of data in a standardized format. Thanks to coding, researchers in the humanities have the opportunity to visualize and analyze their data in different interfaces and manipulate them in various themes. Today, the fact that many software or online databases offer TEI output or that coding editors offer automatic TEI codes points to the widespread use of TEI.

Coding with TEI according to any text’s original structure is another advantage. In addition to an archived text’s metadata, encoded texts can allow the sentence structure, scribbled or unreadable places in the texts to be specified. More importantly, we can transform text into linked data, such as adding annotations to texts or mapping spatial data.
For example, a Microsoft Word document cannot provide the opportunity to analyze selected parts of certain topics such as names, themes, places, dates, or people in the texts in tens of thousands of documents. However, thanks to coding, we can also analyze and visualize selected text sections according to different topics in the texts. TEI Consortium also “provides a variety of resources and training events for learning TEI, information on projects using the TEI, a bibliography of TEI-related publications, and software developed for or adapted to the TEI.”3

The richness of Ottoman archives in different themes and genres, covering the history of nearly 30 countries, has the potential to offer great research opportunities for TEI. It is very important to take advantage of the thematic research, protection, storage, and deep analysis opportunities provided by TEI, beyond merely digitizing documents through scanning or focusing just on OCR technology.

In addition to TEI projects in many languages on history or literature, studies are carried out in the field of digitizing corpora. However, there are only a limited number of initiatives in this area regarding Ottoman Turkish. I hope that a small case study of TEI’s Ottoman Turkish will raise awareness about the potential of this field.
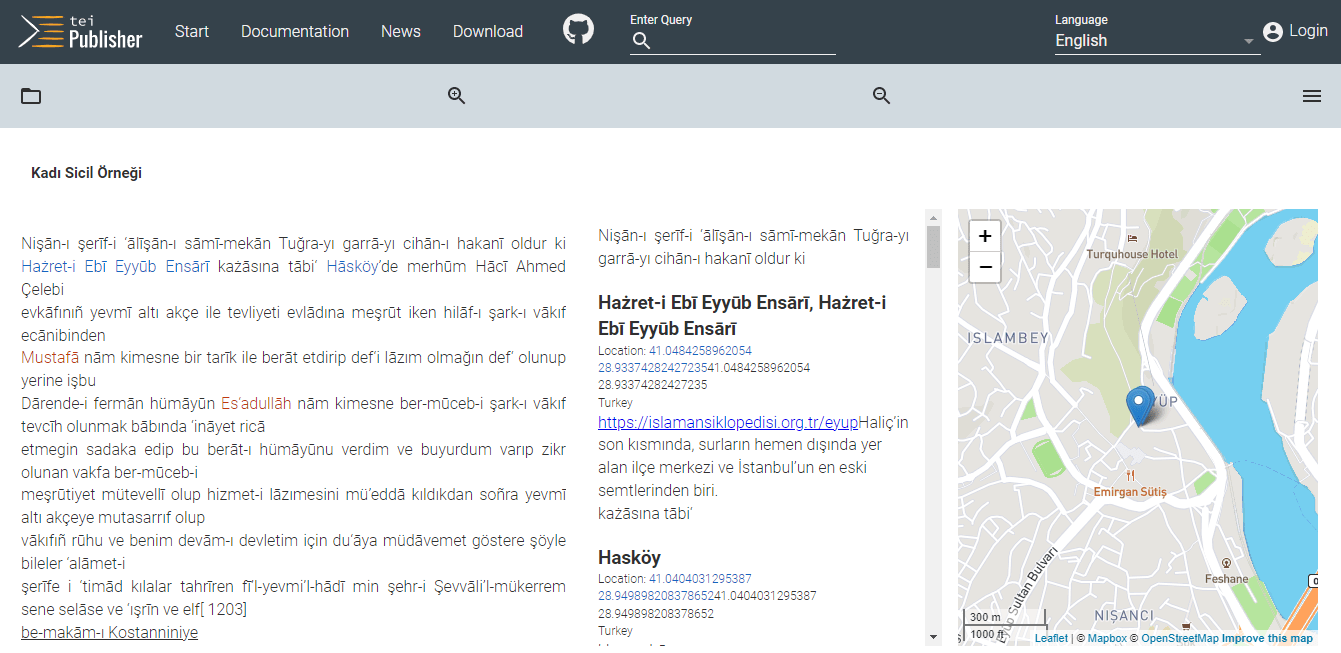
To test the difficulties and possibilities of coding according to the TEI guide, I tried an example from the Ottoman court registers from İSAM Library at the entry level and with a one-page document. I emphasize that this is a limited example to gain insight on potential for TEI for Ottoman Studies, and this test needs some technical updates. Expanding this study according to different types of documents or the number of documents will provide a much more meaningful experience for TEI.
First of all, it is important to organize the TEI header (<teiHeader>) of the metadata section of the document. This section includes the details of the archive, as well as the information about the individuals or the team that are part of coding process. A TEI header is mandatory child element of the root <TEI> element. Hence it should be included at the top of every TEI document. After this part is designed, it is now possible to move on to the coding of the text’s body elements.
The TEI <body> is the part that contains the entire structure of the archived text and the entire body of a single textual unit. In this part, all structural features, annotations, geographic data, annotations, and tags in the primary source are coded. In the TEI guide, tags are designed according to all the possibilities that the researcher may encounter in an archive text. For example, scribbled texts, illegible words, and bold or italic type can be tagged and displayed according to this guide as they appear in the primary source. Spatial data in texts can be automatically mapped via geographic coordinates.
Finding the equivalent of tags designed in English for specific definitions or terms in Ottoman Turkish is one of the complicated parts of coding Ottoman Turkish with TEI. Alternatives for or deficiencies and compatibility with the codes should be discussed with scholars in Ottoman studies to improve application of TEI to this field in future studies. This will occur thanks to the development of continued use of TEI.

This method, which still needs some minor technical corrections, has a very great potential for an easy digitization of Ottoman Turkish documents. It is very beneficial to add Ottoman Turkish documents to the wider information network through linked data and annotations. Thus, while navigating the texts, we have the opportunity to view both the geographical locations and the annotations or the notes simultaneously. Thanks to the tags, we have the opportunity to analyze different partitions in the registers separately.
With the exception of some mandatory layout elements, TEI structure can be customized and changed accordingly to afford any project. Thanks to TEI Publisher, XML data can be easily displayed online. Thus, researchers can easily visualize how the codes are structured and make them accessible.
We hope that the researchers in Ottoman studies will include the opportunities created by TEI in their own projects and contribute to the studies in this field. We have a chance to gain more experience with the benefits and limitations of encoding structured texts using this technique. By engaging more with TEI, scholars can help make texts more accessible to others in the field, while developing appropriate protocols for TEI regarding Ottoman studies at the same time.
- https://tei-c.org/
- Lou Burnard, What is the Text Encoding Initiative? How to Add Intelligent Markup to Digital Resources, Marseille: OpenEdition Press, 2014.
- https://tei-c.org/
One thought on “Text Encoding Initiative (TEI) for Ottoman Studies”