
Text filtering helps researchers target selected, specific data for accurate text analysis results. In my last post, I explored the open-source data cleaning software OpenRefine and introduced how to select or filter certain content of a text by locating keywords. Following this idea, I would like to continue the experiment with OpenRefine to discover another text filtering method applicable for Chinese text.
This post will focus on the Facet tool, which serves the basic and core concept of OpenRefine. Facet allows to cluster and filter data from numerous cells in a given column. The clustered cells share the same feature or are organized in a certain way chosen by the user. For example, the user may cluster cells with identical text, sort numeric text by their range, display dates chronologically, or organize text by length. These different angles of Facet can be used as a combination to narrow down the text step by step for desired data.
In this post’s demonstration, we test OpenRefine with news articles that are obtained from the K-pop website 韩粉乐园 (Hanfen leyuan) between Jan 1, 2020, and May 15, 2020. Fig.1 shows a screenshot of the downloaded plain text in a txt file, which is a mix of article titles, main bodies, and information about the author and publishing date. According to the specific research question of the digital project, a focus may be given to only the title or the main body of the news articles for a meaningful investigation of China-based K-pop media.

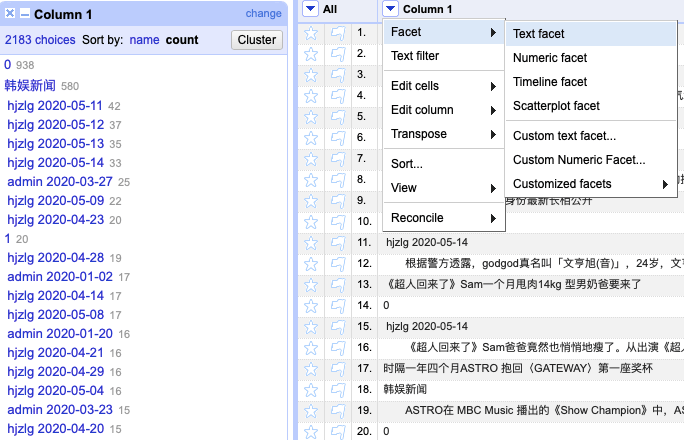
To start, we upload the txt file to OpenRefine and uncheck the “store blank rows” box to create the project “韩粉乐园”, which contains one column of 4574 rows. From the drop-down menu of “Column 1” we move to the “Facet” catalogue, which offers a number of filtering options. In the first step, we may try “Text facet” to get rid of unwanted noise. By clicking “Text facet” OpenRefine generates a list in the sidebar clustering repeated cells. We sort the list by “count”, and this immediately results in a display of frequently repeated data that brings no value to text analysis – for example, 938 counts of “0” and 580 counts of “韩娱新闻.” (fig. 2) We “include” them one by one and then “invert” the list to delete the selected items. (fig. 3)
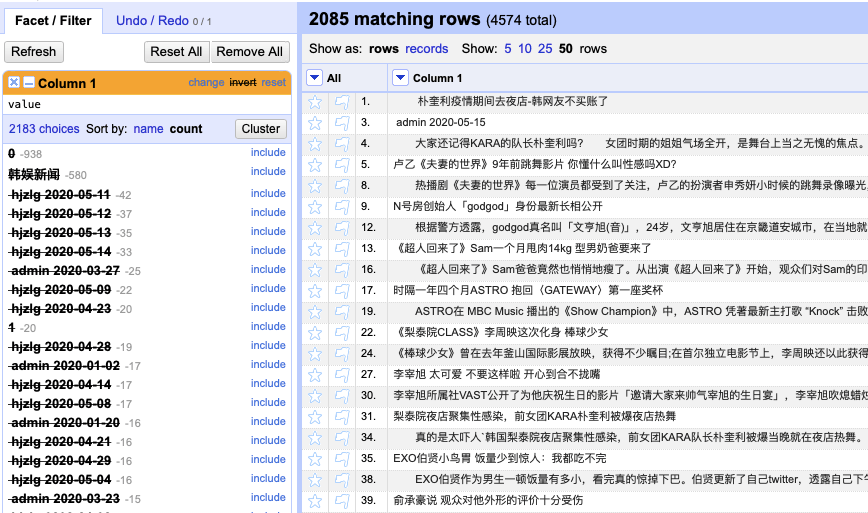
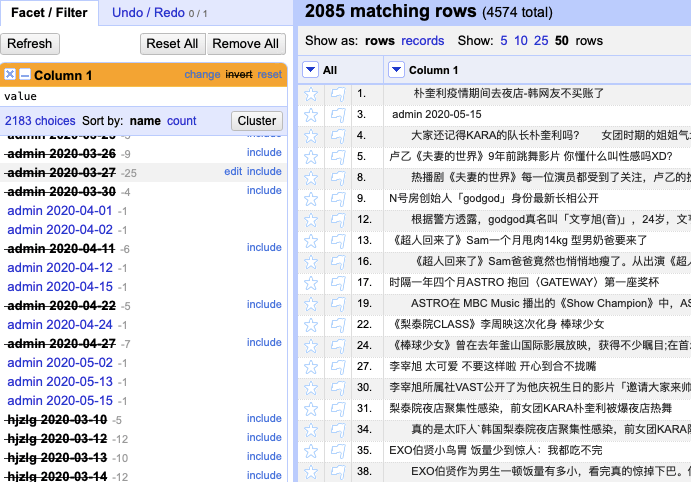
We can further sort the list by “name” to locate less frequently appeared but overlooked items and then delete them as well. As these items are descriptions of authors and dates, they are easily found next to each other under the name of the same author. (fig. 4) After this series of actions, the list is downsized more than half to 2059 rows compared with the original number of 4574.
The remaining text contains only the title and main body of the news reports. At this point, we can use “Text length facet” to distinguish the title from the main body of the articles. This function can be found under “Customized facets” subcatalogue of “Facet.” By clicking it, the sidebar creates a histogram that allows users to choose data from any customized range. We can see from fig. 5 that the cells are clearly divided into two groups with different lengths. Scroll the bar to left or right so that only titles (with fewer characters) or main bodies (with more characters) are shown. (fig. 6) And then by exporting the result, a corpus for text analysis is created.
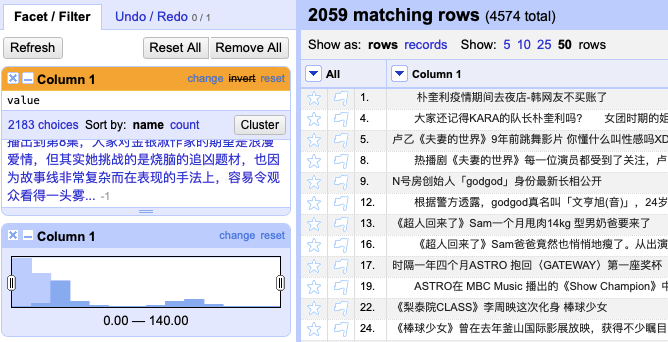


fig. 6 two options of the histogram by adjusting the bar
OpenRefine’s Facet is a powerful tool that filters data within given options. The two examples introduced in this post are straightforward and handy for beginners. “Text facet” identifies recurring terms and allows for further editing. Facet by length enables users to select or filter data according to the length of the cell. This is especially useful for separating text from a mixed environment with length as the identifier, for example, chapter titles of pre-modern Chinese fiction and verse with specific length.
(The demonstrated research project in this post was sponsored by Professor Adam Bohnet at King’s University College in 2020.)
One thought on “Data Cleaning Chinese Text with OpenRefine: Facet”