
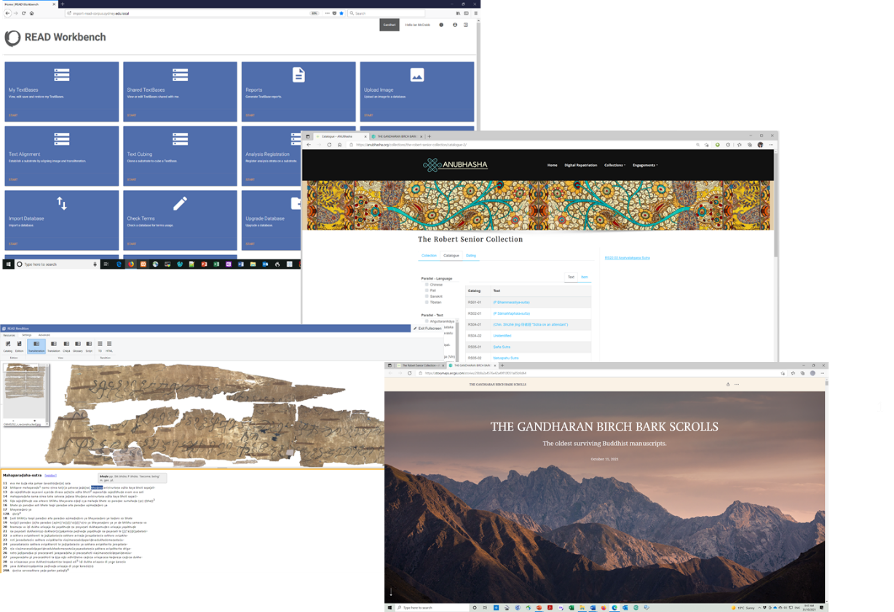
The ‘Research Environment for Ancient Documents’ (or ‘READ‘) is an ecosystem of open-source tools and platforms for the creation of annotated digital texts and art objects, most often used for Indic manuscripts and epigraphic sources. The main experience of a researcher using this system is through ‘READ Workbench’, which is a self-service, collaborative portal for researchers looking to develop annotated ‘TextBase’-s used for advanced philological research, detailed archival work, community engagement, and teaching. An object annotated through READ can be built into other online spaces as a plug-in and exist alongside tools and media to create curated online spaces for teaching and research that can appeal to both researchers and general community members as suits the needs of individual scholars or institutions. In forthcoming posts, I will detail how we attempt to do this with our own research projects through ANUBhasha, our collective of digital South Asianists at the Australian National University (ANU), through the addition of ArcGIS StoryMaps, podcasts, and other media.
The READ development team began working together in 2013. Stefan Baum, Andrew Glass, Ian McCrabb, and Stephen White made up that initial development team, supported by funding received from a consortium of universities. Since the outset, many researchers and technical specialists have contributed tools, textual projects, and other features to this research engine. A corpus collaboration portal, READ Workbench, was developed by Ian McCrabb and Yang Li for a community of users focused on Gandharan Buddhist manuscripts and epigraphic sources. Today, the various users of READ Workbench work on other Indic-oriented textual, epigraphic, and art traditions and share their work across a network of websites and online collections. For example, the University of Sydney hosts many of these on their ‘Gandhāran Buddhist Texts’ site and my ANU colleague, Stephanie Majcher, and I share our own work through ANUBhasha. Some collections, like the University of Sydney’s, focus on a deep philological engagement with a thematic set of collections (epigraphic and Gandharan in this case). Others, like ours at ANUBhasha, pair smaller collections with other kinds of digital media to think about what engaged ‘Digital Repatriation’ can look like in South Asia. READ is a tool that suits a variety of use-case scenarios.
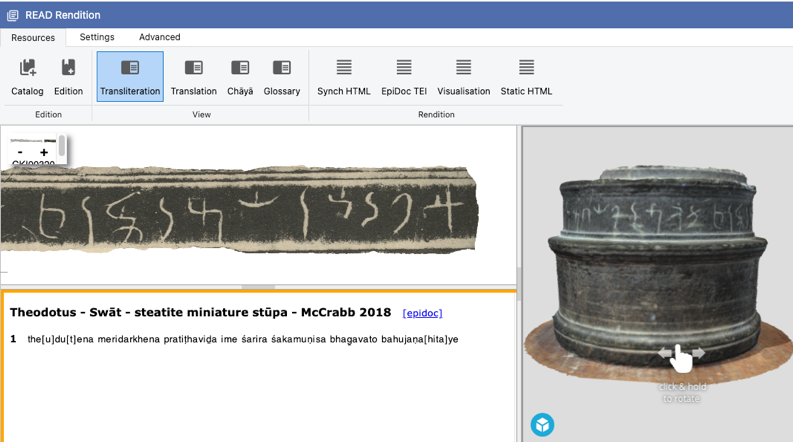
The primary task of someone working with READ is to develop an annotated version of their textual source (usually a manuscript or art object). Many of the users of READ Workbench are using incredibly high-resolution images of birch-bark manuscripts or detailed 3D images of sculptures. In my case, I am starting with digital copies of microfilm copies of 16th-18th century palm-leaf manuscripts from Nepal. The manuscript sources that I work with are roughly 1500-1600 years younger and in better condition than those originally used with READ Workbench, so I find these lower resolution images sufficient for my purposes. This is probably indicative of the kinds of images that would be useful for others who are using more contemporary materials.
Without going into too much detail, creating these annotated and workable copies of manuscripts involves transcribing the text in a Word document along with a small set of diacritics that document physical features of the text object, scribal features, damage, and in the case of my manuscripts, the spaces and holes used to thread together palm-leaf manuscripts. This low-tech and accessible transcription, that many of us do in our own idiosyncratic ways in any case, is paired with and processed along with the images of the manuscript.
The most detailed and time-consuming part of the job is to ‘align’ those annotated textua with the image so that they can be paired with the transcription inside of READ Workbench. This results in a copy of the manuscript that interacts with the transcription. If you hover a cursor over the image features or the transcription, the corresponding version in the other source is highlighted. This intuitive user interface and ability to interact with the physical object (or its visual copy) make it the perfect tool for training and learning codicology and other skills of textual analysis while documenting, rather than as a secondary or tertiary step.
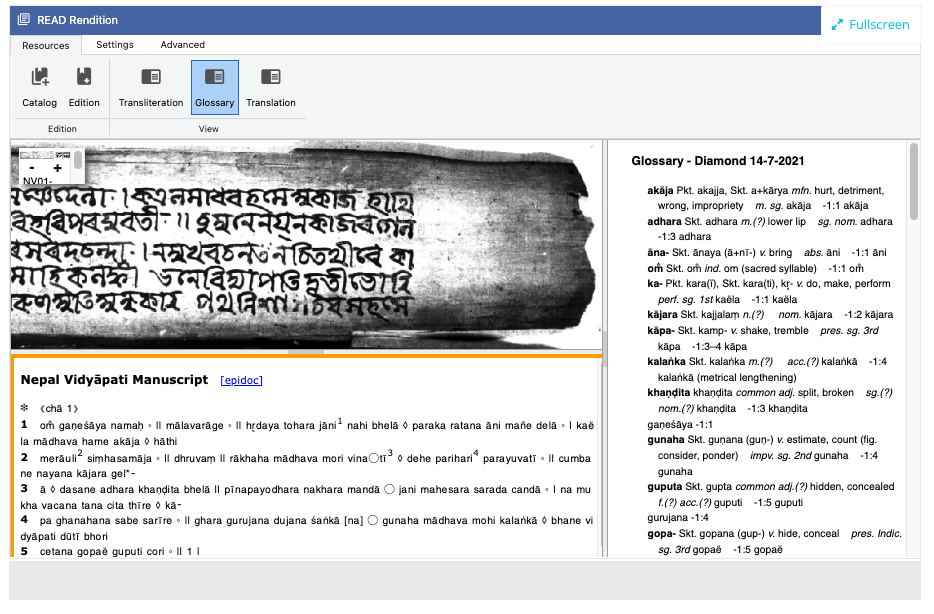
After this core work is finished and depending on the manuscript/art object and the desired end use-case, the ‘TextBase’ developer can add a glossary, critical and diplomatic editions, translation (in multiple languages), and other additional layers of information to fully contextualise the manuscript source. This is both an ecosystem to work within and to display the end of the process of textual analysis, documentation, and translation. These additional layers of information can then also interact with the transcriptions and text images. A cursor can simultaneously highlight the text edition, the place within the manuscript, the lexical item in the glossary, and other information desired. Another useful feature of READ is the ability to export a READ ‘TextBase’ in EpiDoc TEI for use by other scholars and for different kinds of digital textual analysis. READ excels at close reading and detailed philological analysis, but it can live alongside other techniques of distant reading and corpus analysis too.
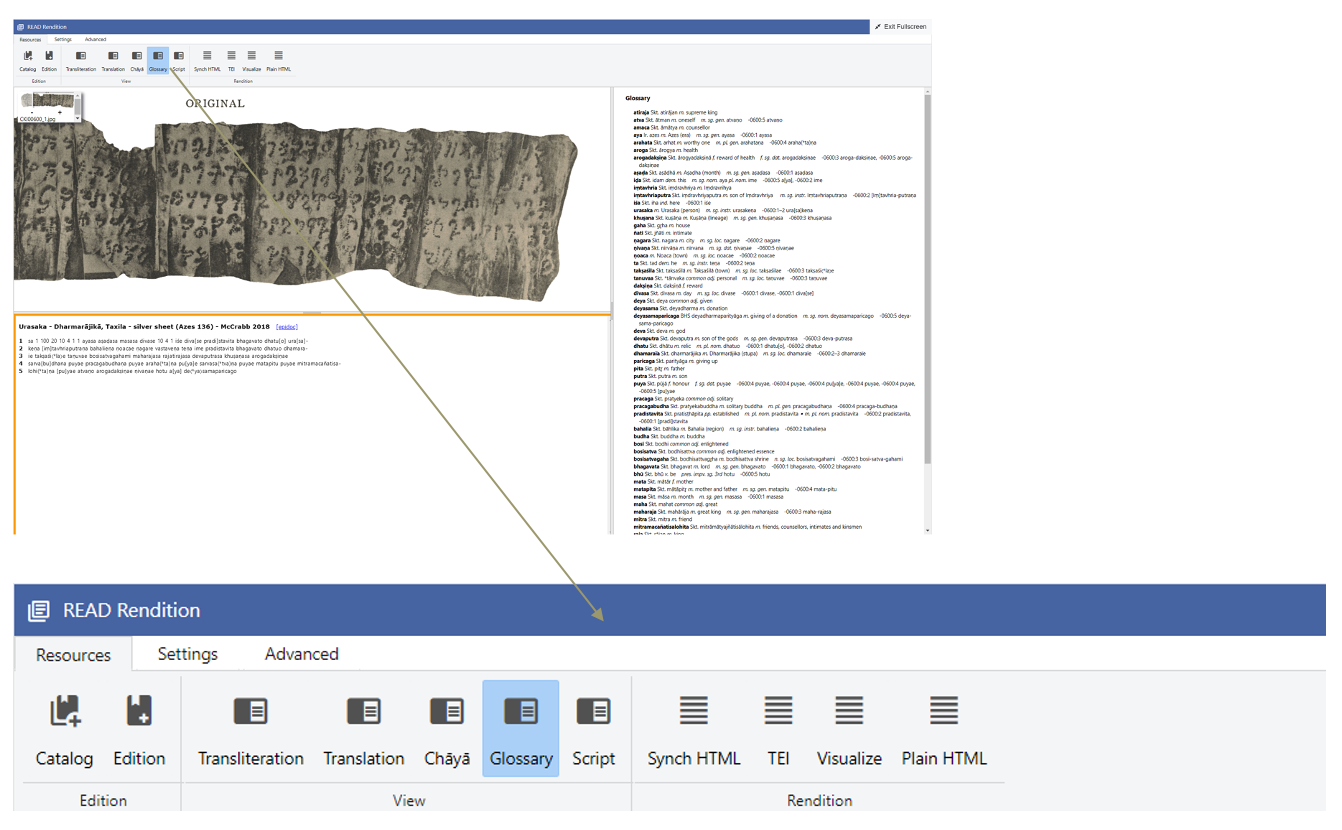
I think other researchers, whose areas or disciplines differ, could benefit from tools like READ. The strength of this tool is in its adaptability. Being able to focus on the physicality of historical documents and art objects with minimal technical ability needed to document those material details allows for the READ suite of tools to be applied to many different historical and archival contexts. The original users of the READ system were primarily Indologists and other Buddhist studies scholars focused on birch-bark manuscripts, inscriptions, and other art objects from Gandhara (present day Northwestern borderlands of Pakistan and Afghanistan), constituting the oldest collections of Buddhist textual history available to us. Since the late 2010’s, the number and breadth of scholars using READ have expanded the collections available to the public. Some of these now include collections focusing on: Upper Indus Valley inscriptions, reliquaries and art objects, Kushana inscriptions, and other Buddhist texts further afield in Southeast Asia. These contexts are closely aligned in linguistic contexts. Because of this, the tools, processes, and applications were refined for working in those material, textual, and languages. However, my own work on Early Modern Maithili songbooks from Nepal is still South Asian in focus, but radically different in approach and linguistic-technical needs. In forthcoming posts, I will explore some of the ways READ can adapt to contexts and how those workflows can be shared in wider communities of scholars and cultural stakeholders through a look at how I process these palm-leaf songbooks through READ to be displayed on an online platform like ANUBhasha.
2 thoughts on “READ Workbench (Part 1): An Introduction to a Text and Image Annotation Ecosystem”