
Report of Gǀui Archiving Project
By Kanji Kato
ROIS-DS Center for Open Data in Humanities/
Tokyo University of Foreign Studies Graduate School
For this post, we have an invited article written by Kanji Kato on Gǀui Archiving Project. Kanji Kato is a project researcher at the ROIS-DS Center for Open Data in Humanities (CODH) in Tokyo, Japan. His work focuses on the grammar description of Japonic languages and the digital archiving of endangered languages.
I am grateful to Professor Hirosi Nakagawa for the supervision of this article.
This article aims to provide an overview of an ongoing language archiving project. Professor Hirosi Nakagawa (Tokyo University Foreign Studies) and Emeritus Professor Kazuyoshi Sugawara (Kyoto University) have conducted on linguistic and anthropological research of the Gǀui people of Botswana. Nakagawa and his students, including me, have been working on an archiving project of the Gǀui language material collected by Sugawara.
Overview of Gǀui
The Gǀui people live in the central Kalahari reɡion. They continued to live a hunter-gatherer lifestyle until around the 1970s. However, government-led settlement began at the end of the 1970s, and fewer and fewer people are living the traditional lifestyle.The map below shows the main settlements of the Gui people.
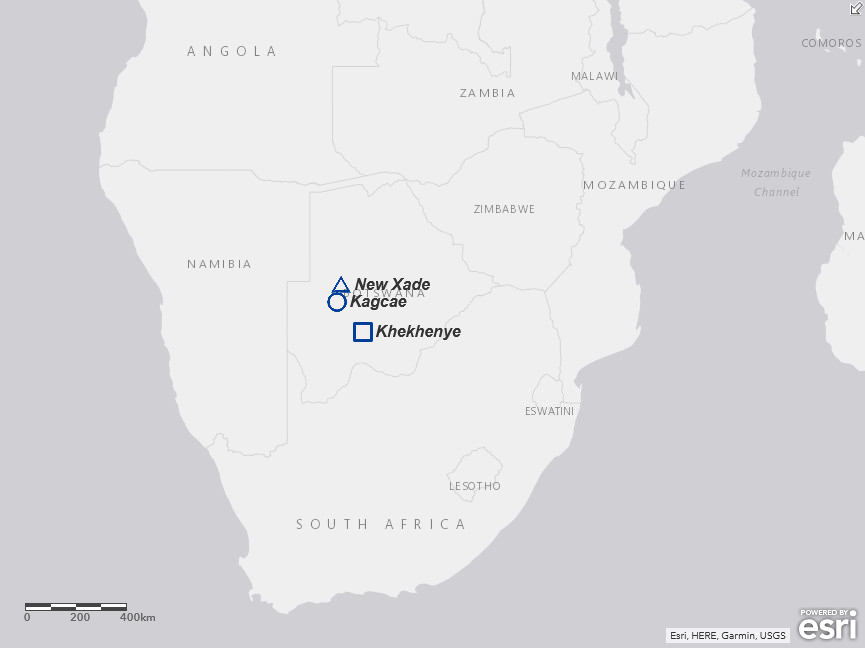
Main settlements of the Gui people (drawn by Kimihiko Kimura)
Gǀui [ɡǀúī] (ISO 639–3 code gwj) is a Kalahari Khoe language, Khoe-Kwadi family, spoken by approximately 800 peoples in Gǀui communities in Ghanzi and Dutlwe Districts in Botswana. Like most Kalahari Khoe languages, Gǀui is an unwritten language, so its orthography is still to be developed. It has the largest phonemic inventory in the Khoe-Kwadi family, containing 90 consonants and 10 vowels, and it has been a challenge to develop the orthography both linguistically and practically. In accordance with the recent encouragement of orthographies of local languages initiated by Botswana’s government, Nakagawa is currently starting a practical Gǀui orthography project, which is closely linked to the present Gǀui linguistic archiving.
Archiving of Discourse Material
Despite the recent progress of linguistic documentations of the southern Khoisan languages, there has been little linguistically edited textual material, particularly of Kalahari Khoe languages. In the case of Gǀui, however, Sugawara started to accumulate audio recordings and transcriptions of natural discourses spoken in Gǀui between 1994 and 2013 for the purpose of his anthropological research. The length of recordings, which last approximately 70 hours, and the size of texts, which cover 110,000 words, are an extremely large language resource in the Khoisan languages. This material includes narratives on a diverse range of topics. For example, it includes the myth of how a trickster called piisiǀuaɡu stole fire from an ostrich so that people would handle fire, and a true story about a lion killing a man. For a long time Sugawara’s data was not properly digitized nor processed for the purpose of preservation or further future linguistic analysis.

Handwritten field note by Sugawara. Gǀui transcription is on the left-hand page, and the Japanese translation is on the right-hand page.
Nakagawa has launched a research project (JSPS KAKENHI 20H00011 and 22K18249) to archive this vast amount of material. First, all of Sugawara’s handwritten notes were scanned and digitized. This has already been completed. Next, the handwritten notes were transcribed into phonemic transcription. This work is about 90% complete, but there are some reading errors that need proofreading. Also, transcribed texts were merged with recordings by using a tool for natural discourse editing, ELAN. Recordings are separated by speaker and by utterance, and all utterances are given a start and end time. This process is about 66% done.
Although the proofreading has not yet been completed, about 50,000 words of recording and text separated by utterance are available at this stage, which is the largest corpus for the southern African languages.
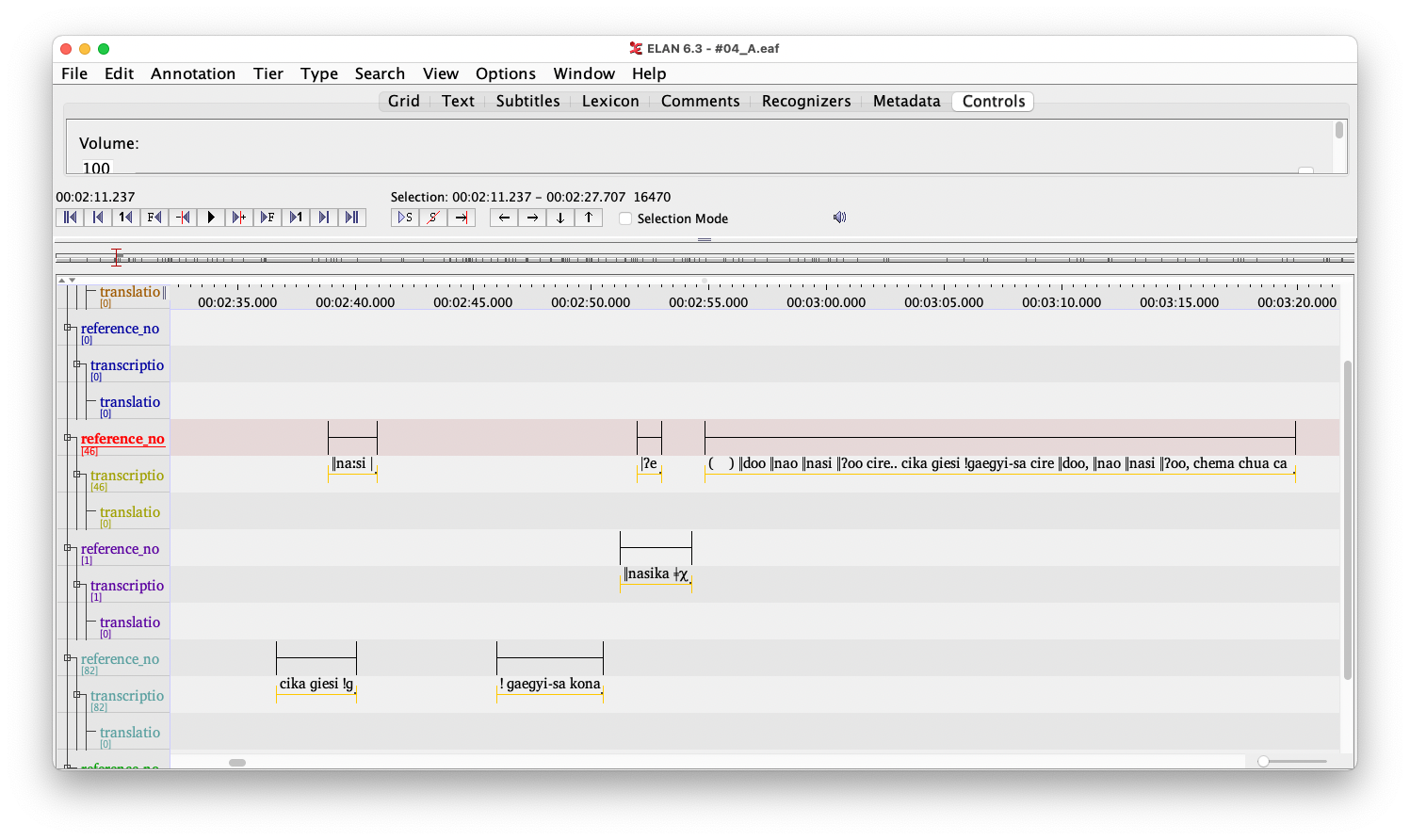
Text and audio material integrated with ELAN
Future work will focus on calibration work and the assignment of time information to utterances. We are also considering segmenting the utterances word by word and morpheme by morpheme, and assigning glosses for them. In the future, it is envisaged that text will be marked up according to the Text Encoding Initiative Guideline.
By 2025, we aim to be able to conduct an initial survey of the frequency of phonemes in textual materials as a first phase. In a second phase, during the two years from 2025 to 2027, we will then discuss which parts of the data can be published and how they can be masked, taking into account the protection of personal data. Based on the discussion, the data will be made public. In the second phase, the parts of the data that do not contain personal information will be used to develop language materials with an orthography for native speakers.
Author: Kanji Kato
[twitter-follow screen_name=’digiorientalist’]
[twitter-follow screen_name=’So_Miyagawa’]