
A quick API solution for a Chinese text classification task
– and its limitations.
This is a guest post by Tilman Schalmey: ORCID | Trier University .
Featured image: Tilman Schalmey.
In my current research project at Trier University’s China Institute (CIUT), I’ve attempted to use Open AIs API, hoping to speed up some of our work. In this post, I want to share my experience.
In our project, we want to gain some insights into discussions taking place on the Beijing-based Q&A internet platform Zhihu 知乎. In particular, we’re interested in questions and answers related to the global semiconductor shortage, and the answerers’ argumentation. To somewhat quantify what is going on, we identified several typical ways of reasoning in the answers: historical, technological, nationalistic, China-critical, geopolitical and off-topic. I don’t want to go into too much detail here and will assume for the time being that those labels are rather self-explanatory.
We have curated a list of 40 very »hot« (according to Zhihu’s obscure algorithm) questions on the matter, plus the twenty most-liked answers to each of these questions – a total of 800 answers, or more than a million Chinese characters. An answer can be short, just a few sentences, but a majority of the answers are really long. Some even have a few thousand characters – several standard pages! It appears the average user doesn’t mind long posts, as long answers regularly get thousands of likes from other users. But reading through hundreds of long posts and manually labelling them is an enormous task for lazy researchers on a tight time budget. Experiments with topic models were not particularly promising, and, after having read and labelled only half of the posts in our corpus, we started to hope that ChatGPT could offer a shortcut to this arduous manual labour.
ChatGPT had already caught my interest and I was fascinated with some of the outputs. Could we also ask Chat GPT to assist us with the labelling?
I ran a mini-pilot on a random answer to get a feeling if it was even worth a more serious try, so I went and asked the chatbot:

This is what I got:

Undismayed by a Chinese-English mixed language query, not only did Chat GPT assign the exact same labels as I did – China-critical, technological and geopolitical – it also provided a few bits of understandable reasoning for its choice. Could I have avoided all my previous, laborious hand-labelling? I needed to verify this with a larger sample.
In exchange for my email address plus a few clicks on “pictures showing traffic lights”, I got an API key. Reusing some code snippets from open AI’s playground, I quickly pieced together some Python code to loop through the answer posts from Zhihu and retrieve labels for them.
At this point, it’s worth mentioning that the API-received answers are not processed by the exact same AI version that is used by the ChatGPT, but by the earlier 3.5 versions. From the twelve available models, I chose the text-davinci-003, because the documentation claimed it could “do any language task with better quality“ (https://platform.openai.com/docs/models/gpt-3-5) than some of the other models.
In my first attempts, I ran a similar query as in the example above and retrieved a list of labels for each answer. From a purely programmatical point of view, it went really well. But after a few test runs, it became apparent that almost all the labels were almost always assigned to almost all the answers. It’s not too surprising, though: the language model identified terms related to the label, so e.g. answers with terms like “demand” would easily be labelled “economic”. The longer the answer, the more likely more suitable labels could be found. At this point, the paint was beginning to crumble.
I decided that I had come this far and wouldn’t give up so easily, so I had my computer repeat this query for all the manually labelled answers to one of the questions from our corpus: “ASML 拒绝美国「禁止对华出售光刻机」要求,荷兰阿斯麦为何有底气向华盛顿说不?” (“ASML rejected the United States’ request to »prohibit the sale of lithography machines to China«. Why did the Dutch company ASML have the confidence to say no to Washington?”)
GPT labelled diligently… one answer… two answers… three answers and… error. Too many tokens. Really?! By design, the API limits queries for this model to 4097 “tokens” – including the response. I had carefully taken into account the length of my query by cutting the answers I wanted to label after a little more than 3000 characters to ensure this wouldn’t happen. Knowing how flippantly the labels were assigned, it was easy to accept truncating the data for the time being.
I turned to the API documentation, trying to understand the meaning of “token”. A token, they say, is “4 chars in English“, “3/4 words”. Now, as often, things get painful for users of Chinese (or any non-Latin script). I experimented a bit and wound up asking the chatbot:

The bot answered truthfully that “[…] simple Chinese characters like 我 (wǒ) and 你 (nǐ) may be represented by a single token, whereas more complex characters like 龍 (lóng) and 繁 (fán) may be represented by multiple tokens. […] Therefore, it is difficult to give an exact number of tokens that a Chinese character would usually use in OpenAI’s API.”
In the end, it worked well for me to assume that one average simplified Chinese character equals approximately 1.7 “tokens”. Alternatively, one could implement a byte pair encoding (BPE) tokenizer in order to get the exact token length for each character.
Automatically labelling 60 more answers only confirmed my first impression: GPT 3.5 light-mindedly assigned multiple labels, too easily triggered by certain keywords. I decided to limit the result to one “best” label per answer – would this yield better results?
With all my token-greedy Chinese characters, it didn’t take long until I reached the end of my free trial. As regular pricing is by 1K tokens, with a corpus of 1M+ “expensive” Chinese characters, my ambitions slowed down quickly. I did the maths, roughly: labelling the rest of my corpus would cost around 20 USD.
To this point, I had AI labels for 156 of the 800 Zhihu answers I was interested in. In 47.4 % of the cases (a random label generator would have achieved 14 %), the AI had chosen the same label as me. This was still inconclusive, as in many cases it was hard for me to decide what was the best label for a specific answer. So I made another comparison: Was the main AI-assigned label included in the list of labels I had found myself? Say I had assigned geopolitical as the main label but nationalistic as a secondary label, I would still consider nationalistic as the correct label when assigned by GPT. Counted like that, GPT labels would be 78.2 % correct. (With an average of 2.4 labels I assigned per answer, a random label generator could have scored 34 %.) Considering that it took me several days to skim the answers and hand-label them, arriving at this result in just a matter of minutes is still very impressive.
Tilman

ChatGPT
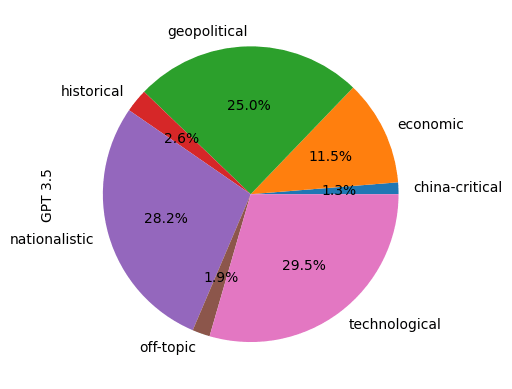
Being most interested in the more subtle content like self-critical nuances hidden in a patriotic comment, it turned out that GPT-3.5 couldn’t help us. As seen already in the small sample (above), GPT was much more likely to miss China-critical or nationalistic arguments than I was (and for sure I didn’t see everything myself). On the other hand, a purely patridiotic comment was labelled “China-critical”, because it quoted from and complained about a China-critical article published in Western media.
In the end, GPT in its current version proved impressive but useless for our task. It also is somewhat expensive for a project lacking funding for third-party services. There’s still some hope, though. GPT-4 is on the way, and also my application for educational access. So I might have to withdraw this judgement faster than I would like.
On the bright side, the API is well-documented, easy to implement and fast. Set on a less complex labelling task, GPT-3.5 might already prove helpful to researchers who want to roughly explore their corpus of brief texts – limited by the per-query token limit – if they have the necessary cash.