
Since 2006, the French linguist community has had a tool for depositing the sound sources that document the world’s linguistic diversity. Named Cocoon, for “COllections de COrpus Oraux Numériques”, this technical platform was then opened to all researchers wishing to create, structure, make accessible and archive sound corpora composed of audio recordings accompanied, in a third of cases, by annotations and transcriptions. It seemed to me that within the framework of Digital Orientalist, it is interesting to make this tool known. It is both elaborate in its conception and simple in its use.

Uploading data to Cocoon
Researchers who deposit in Cocoon are accompanied by its designer and manager, Michel Jacobson (CNRS, Huma-Num) and by a second manager, Séverine Guillaume (LACITO). Prior to any project, they explain to researchers good practices in terms of recording, modeling and formatting their resources. This advice concerns the digitization of analogue media and the preferred formats and coding, or the need for naming and data classification plans. But also, even before making the recordings, it aims to ensure that the recording is the best possible, making the most of the equipment used by the researchers.
Once the sound files have been created and the analyses performed, contributors can prepare their deposit. This can be done either by batch, when the quantity of data is large, or by unit thanks to a dedicated deposit interface. The producer can then fill in fields from the qualified Dublin-Core and build their collections. The example below shows a classic structure of a researcher’s collection, ordered by field and chronologically, as presented in the consultation interface.

Viewing the data
Once the deposit has been made and if the license allows it, the recordings, their transcriptions, and their translations are accessible to all. The data (metadata and files) can be consulted and searched: faceted search on the metadata, full-text search on the annotations, geographical search on the recording locations, and, finally, search in the collections.
Referencing is optimal since the platform assigns a DOI to each level of granularity, i.e., an entire corpus can be cited as well as an isolated record.
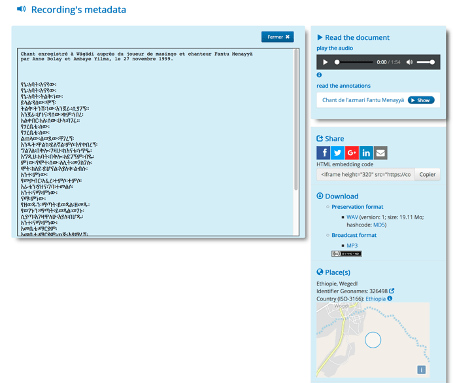
Data enrichment
The metadata is described following the OLAC (Open Language Archive Community) model, which is an extension of the qualified Dublin-Core format (see the cataloging guide here). It is exposed through an OAI-PMH repository, a SPARQL access point or a web-based data publication. One of the strengths of Cocoon is the use of repository-aligned metadata that allows for the enrichment of accessions with other data published elsewhere on the Web.
Thus, additional data on collectors, interpreters, and translators can be added thanks to the reference pivot represented by the VIAF (Virtual International Authority File) identifier. In this case, the interrogation of other complementary warehouses (BnF, ABES, HAL…) is done automatically and dynamically, because the interrogation protocols are standardized.
Of course, the work of aggregating new data is particularly important for languages, since linguists were the initiators and remain the first users of the platform. Each of the languages used has a page containing descriptive, qualitative, grammatical and bibliographical information, etc. The pivotal reference is given by the ISO code of each language, composed of three unique letters. Thus, English is designated by eng or Amharic by amq. The page queries the Lexvo.org, WALS, PHOIBLE, and Glottolog databases. If their data are well structured, their query protocols are not. So it is a regularly updated back-up of these databases that is used to feed the pages present in Cocoon from a rdf triplestore. On the other hand, dbpedia.org, which is a structured extraction of Wikipedia data, is queried dynamically.
Archived data
The work on the archiving of these data is particularly careful. Cocoon is a service transmitting its files, on behalf of researchers, to the digital archiving service of CINES (Centre Informatique National de l’Enseignement Supérieur). The organization of this transfer for permanent archiving has been built on the model of the ISO OAIS (Open Archival Information System).
The assignment of DOIs and submission to a repository means that data cannot be deleted or modified, even though it may have multiple versions. This is a strong obligation that researchers must understand and accept before committing their data to Cocoon.
Conclusion
With over 15,000 recordings, the oldest of which date back to the 1930s, this platform is a veritable goldmine for the world’s oral resources. It is also an example of good practice in storing and sharing, organizing and documenting, opening up and preserving researchers’ data from acquisition to re-use.
One thought on “Cocoon: A Platform for Documenting the World’s Languages”