
In a previous post, I described the preliminary work to do automated analysis on poetry. I now describe the actual code that one could run on it, and I give away the code.
The code and the resources are now freely available on my GitHub repository. If you want to understand this well, it will be good to download those files and open them, or keep them open on the repo. I chose the Psalter to do this exercise as they are among the most well-known poetry. Obviously, the concepts introduced here can be applied to any poetry.
I developed four functions:
- A function to read the number of characters a line in the Psalter has (already discussed).
- A true/false check if a Psalm-verse consists entirely of words from the word list.
- A function to return all words of a Psalm-verse not contained in the word list. This is a helper function for number 4.
- And finally it has a function that will give back all Psalm-verses that are made up of words from the word list, with xamount of allowed words in the verse that do not occur in the list. This function has three modes: to return the numbers of verses that match the criteria, to return the texts of verses that meet the criteria, or to return both.
The second function is on lines 29-37:
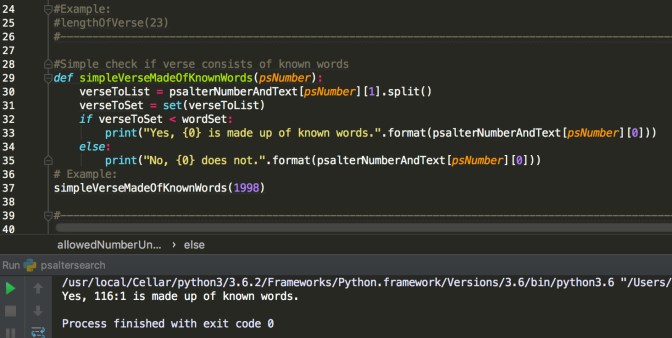
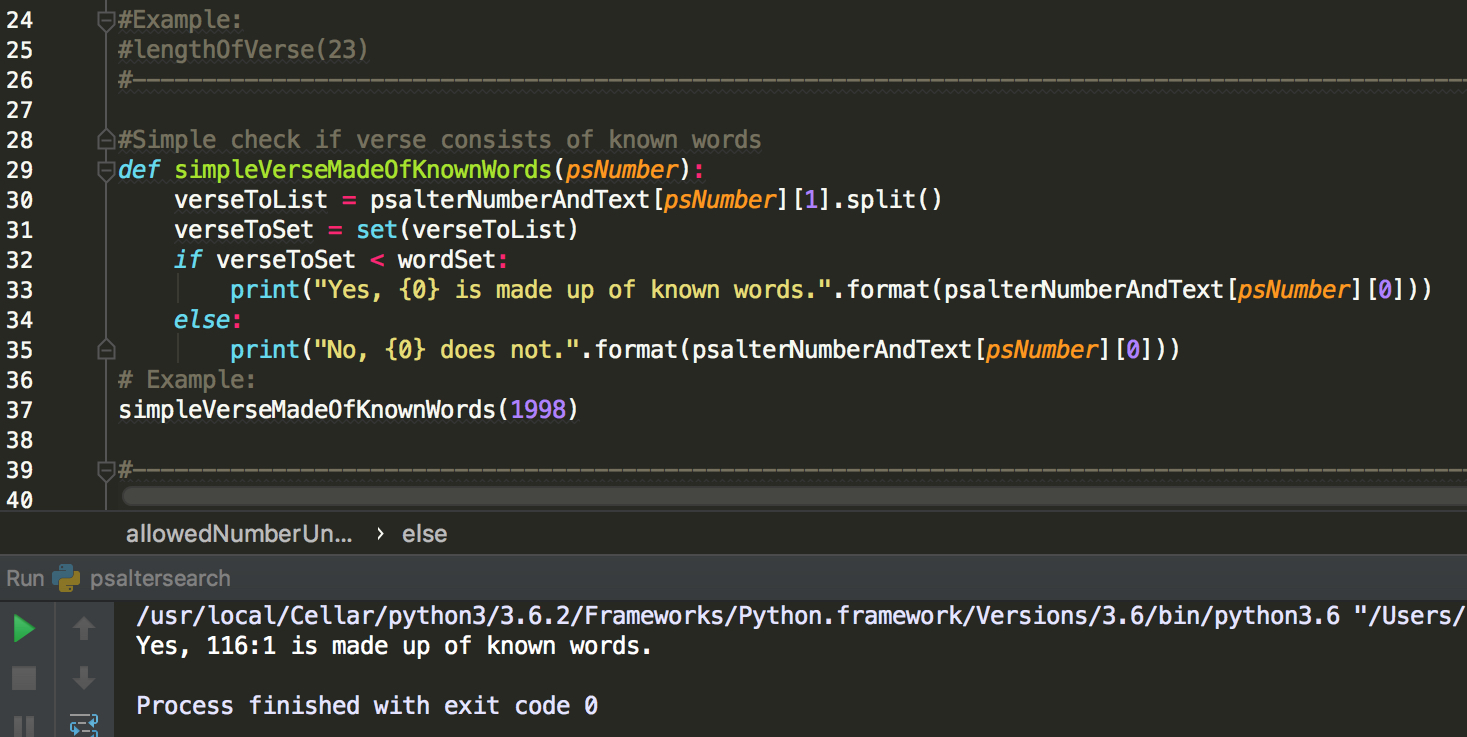
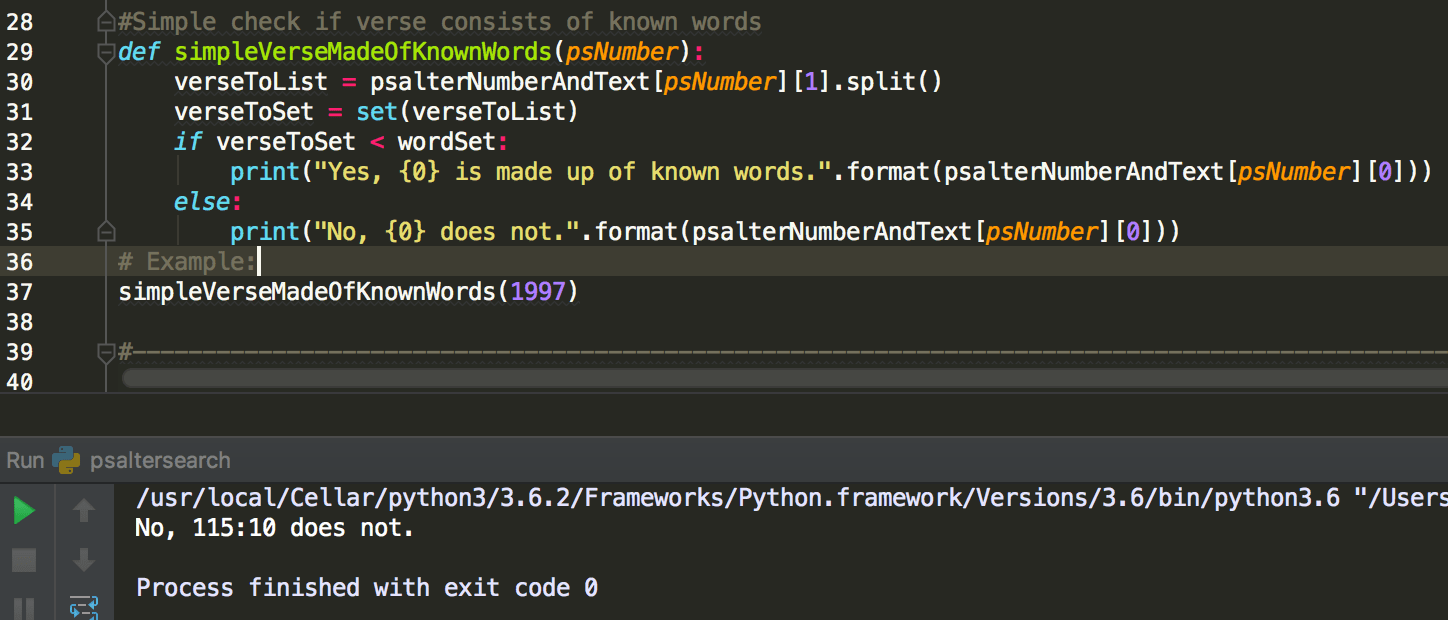
This function takes a verse and checks word by word if the verse is made up of words from a predefined list. In this example, I built up a list of words that are commonly used in Mass or are cognates. I make use of the set functionality in Python. Note that I did not make the function require an input of chapter number / verse number, but rather only one number that encapsulates both. Thus in the two examples above I use 1998 and 1997 to represent Psalm 116:1 and 115:10. This is not really human-readable or user-friendly, but is sufficient if we want to use this function for machine purposes, such as looping through all verses.
The third and fourth functions run from line 43 to 77:
The function allowedNumberUnknownWords takes two inputs; a number to indicate how many words not on the list we will allow, and the mode in which we want to output the result.
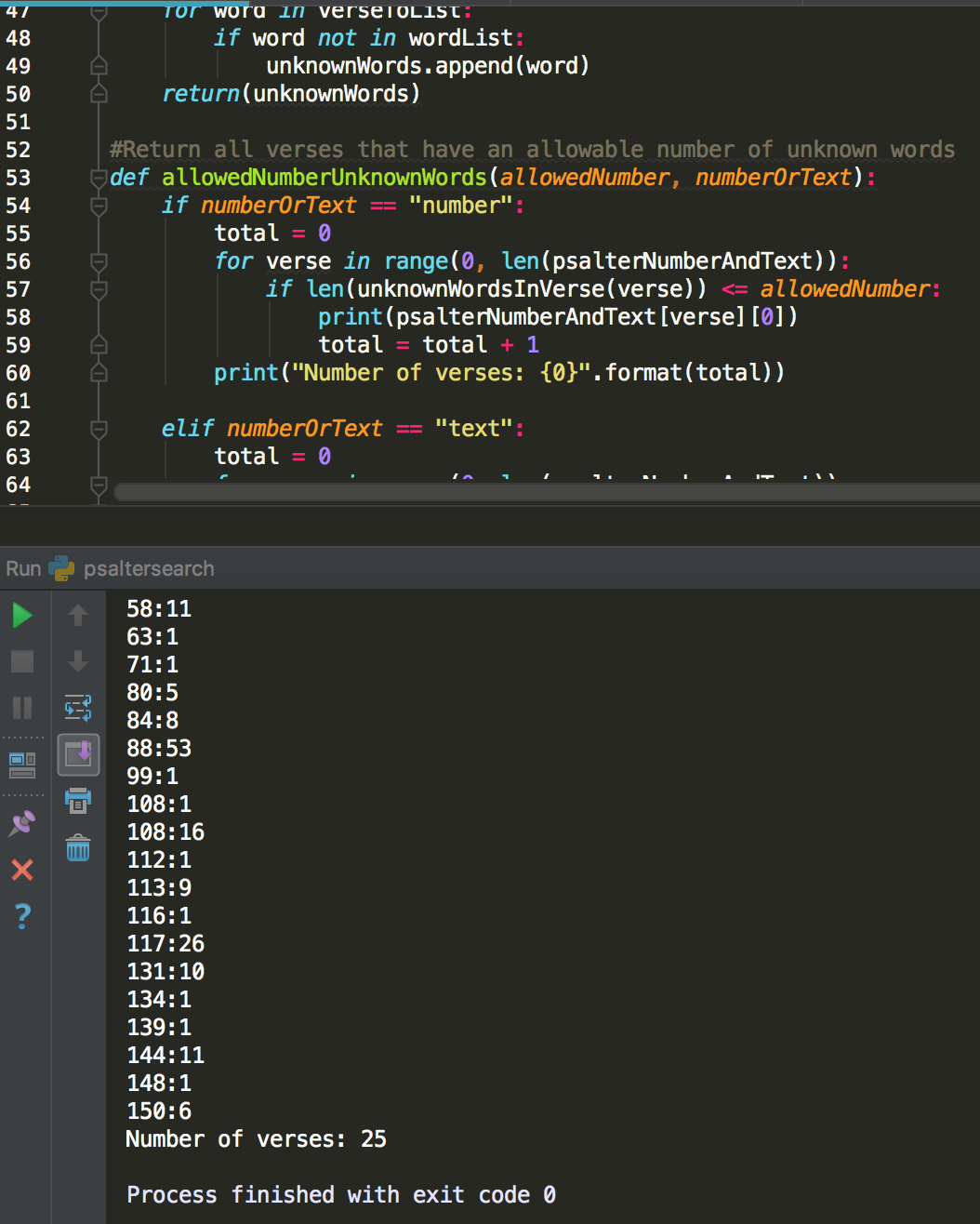
The first mode is to give back only the chapter/verse numbers of those verses which satisfy the conditions. It loops through the verses and prints the number of the verse if it only has x or less number of words foreign to the word list. For each each, it does so by calling the function unknownWordsInVerse, which loops through all the words in the verse and checks them individually against the word list. If the word in the verse does not appear in the list, it is appended to a list unknownWords, which is returned. The main function then checks the number of that list (its length) against the number of allowed foreign words.
The result is a list of psalm verses of interest, with a final print of the total number of verses found.
Of course, normally we would fetch those verse numbers and the unknown words in new lists so that we can do subsequent analysis on it. For example, we can add the unknown words to the list of words, to expand it. Iterated as such, we could find out in how many steps we can encapsulate all verses of the Psalter.
The next mode of the function spits out the texts of the psalm verses found.
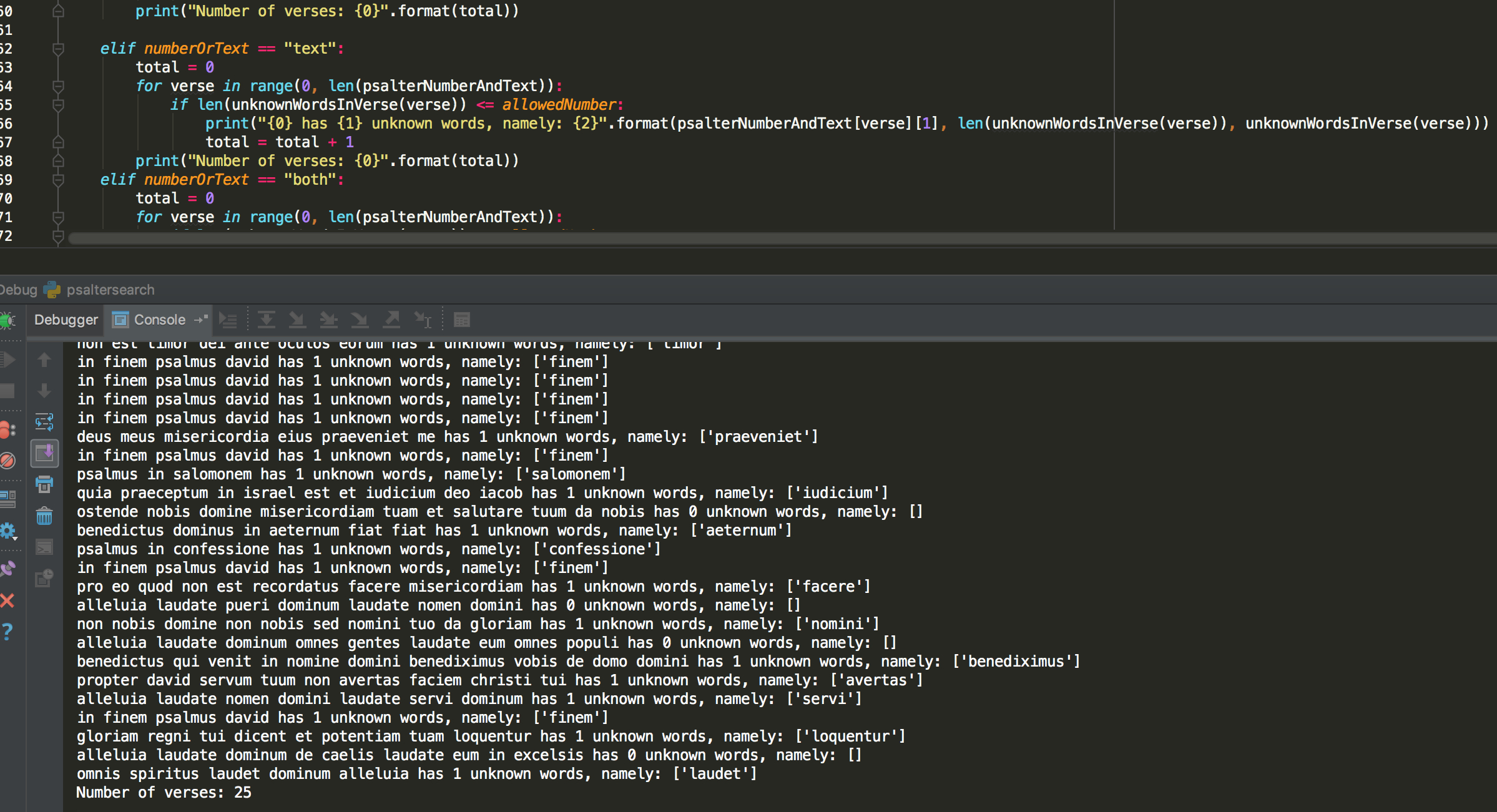
It also gives the number of unknown words and lists them. I have done this in a simple fashion. For example, if no unknown words are found, it still tries to list the unknown words, which then outputs “namely: []” which looks a bit odd.
The last mode of the function gives a fuller rendering of the results:
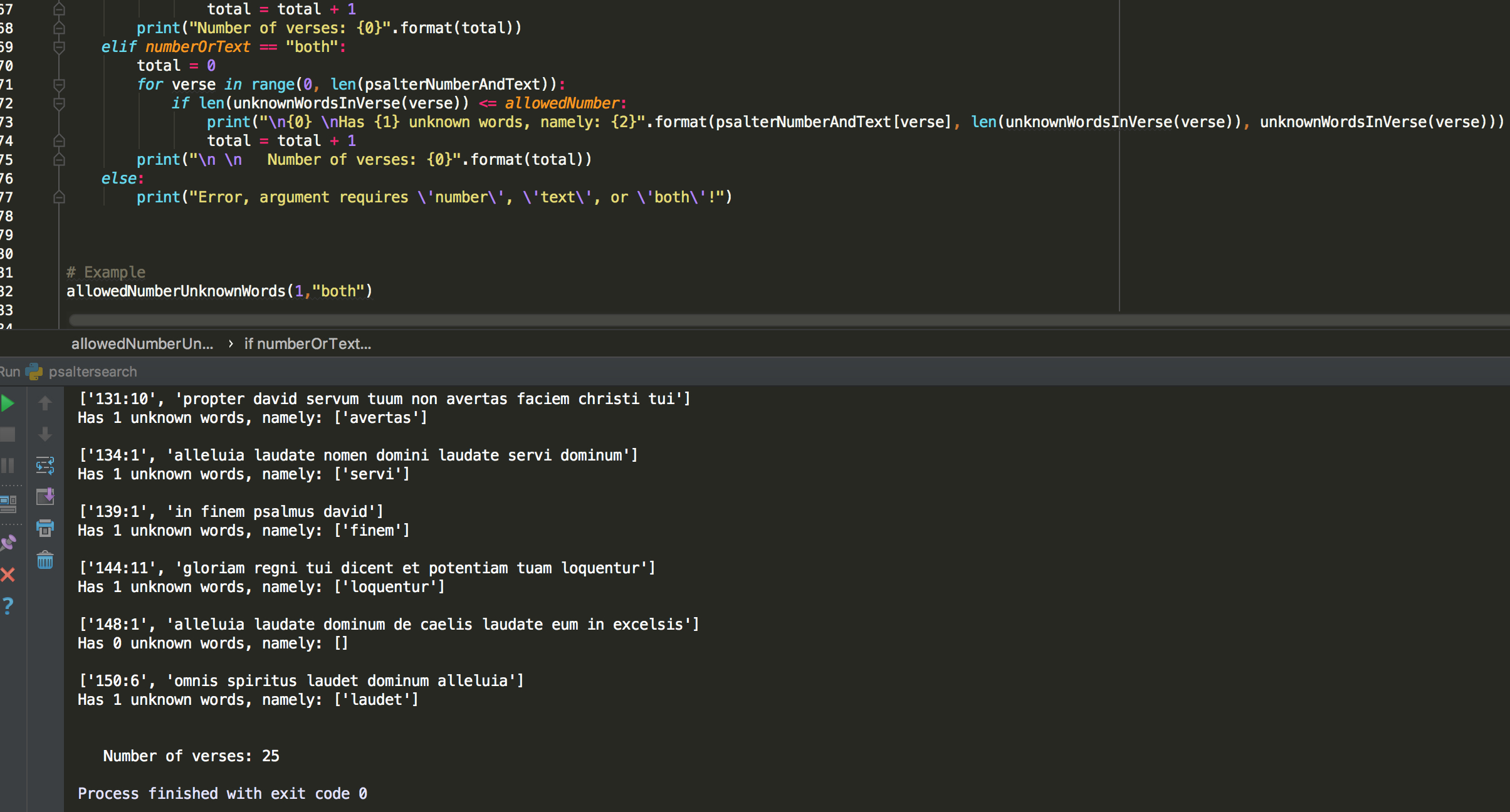
This is probably the most directly useful mode of the function, which is highly human-readable. The other modes are more suited as a first step towards a deeper, computer-supported analysis.
Expansions
By printing out the results, we can gain quick insight in the corpus of the Psalms. For example, we should note the high frequency of finem as a foreign word. Since the meaning of this word is easy to guess (‘end’, like the French fin or the English finite), we might as well add it to the word list and see how that changes our search results. We may want to see how the results differ if we allow for 0, 1, or 2 words not on the list, or automatically add words to the word list if they have a very high frequency in the Psalter corpus. We may want to build a way to find not only the exact word that we added as a cognate, but all its derivatives. By adding functionality little by little, we can see that coding is actually not that hard and that meaningful results come about quickly.
Have a look at the repository and try it out yourself!
One thought on “Tackling Poetry with Python (2)”