
This is a guest post by Erica Biagetti
In my first post as a guest contributor to the Digital Orientalist, I discussed the Sanskrit WordNet, a database for studying the Sanskrit lexicon, modeled on the original Princeton WordNet for English and designed to be used in conjunction with WordNets for two other ancient Indo-European languages, namely Ancient Greek and Latin. I will return to discuss the Sanskrit WordNet in my next post. With this post, I remain within the realm of computational linguistics applied to South Asian languages, but I leap two to three thousand years to introduce the new multilingual parallel treebank—or rather the forthcomig multilingual parallel treebank—of speeches by Narendra Modi (Prime Minister of India) in Hindi, Marathi, Telugu, and English.
But let’s not rush too quickly. Perhaps not all readers of DO are familiar with these tools—treebanks—that computational linguists are so fond of. Therefore, before introducing this new project on which I am working with colleagues from Ca’ Foscari University and the University of Pavia, I will briefly introduce multilingual parallel corpora and treebanks. Those of you who share an office with computational linguists and witness their daily discussions on whether a dative complement should be labeled as an iobj or an obl can skip ahead.
Multilingual parallel corpora are collections of texts, each of which is translated into other languages than the original. The simplest case is where two languages only are involved: one of the corpora is an exact translation of the other. Some parallel corpora, however, exist in several languages. Texts contained in parallel corpora are aligned at the sentence or phrase level, allowing for easy comparison and analysis of corresponding textual units.
Linguists can use parallel texts to identify similarities and differences in syntax, lexicon, discourse, and other linguistic layers. By examining parallel texts, researchers can gain insights into the linguistic structures and features of different languages (Bonch-Osmolovskaya and Nesterenko 2019). For example, parallel corpora have been used to study word order variation in different languages, the distribution of grammatical categories, and the use of discourse markers (see, for instance, Bader and Häussler 2010; Yang and Chen 2015, Lixun 2001). Therefore, while they have been employed originally for the training of machine translation systems, multilingual parallel corpora have become increasingly important in contrastive linguistics, lexicography, translation studies, and studies on second-language acquisition.
Multilingual parallel corpora provide a unique opportunity for cross-linguistic comparison, as they give access to large volumes of comparable linguistic data. However, finding parallel data suitable for corpora is extremely difficult. The largest volumes of translated documents consist of contracts, legal documents etc., which are often confidential. Software localization also produces lots of translated text, but these texts are rarely useful for corpora because they contain highly specialized language, often not the common natural language. The Bible is also a good source of parallel texts but, being a sacred text, its translations are often very conservative.
With the term “treebank” we refer to a corpus of syntactically annotated texts. Syntactic analysis is carried out based on other levels of annotation such as lemmatization, assignment of part-of-speech tags, and morphological analysis, often followed by the addition of semantic or pragmatic information. In the design of a treebank, two main models of representing the syntax of a sentence can be distinguished (Abeillé 2003: xvi-xviii). The model based on Generative Grammar analyzes the sentence by breaking it down into intermediate constituents, which can in turn be broken down into other phrases until reaching the word level. The hierarchy of constituents resulting from this analysis can be represented through a tree structure. Consider the tree resulting from the analysis of the sentence ‘The development journey of Indian society spans thousands of years’, taken from the corpus under investigation:

Syntax tree created by the author using Syntax Tree Generator.
In the model based on Dependency Grammar, instead, syntactic analysis consists of identifying direct dependency relations between the words of a sentence, without the intervention of intermediate constituents. By foregoing the separation between deep and surface structure of the sentence (as in the original formulation of Generative Grammar) and its division into constituents, the dependency-based model proves to be more suitable for analyzing languages that exhibit free word order and discontinuous constituents.
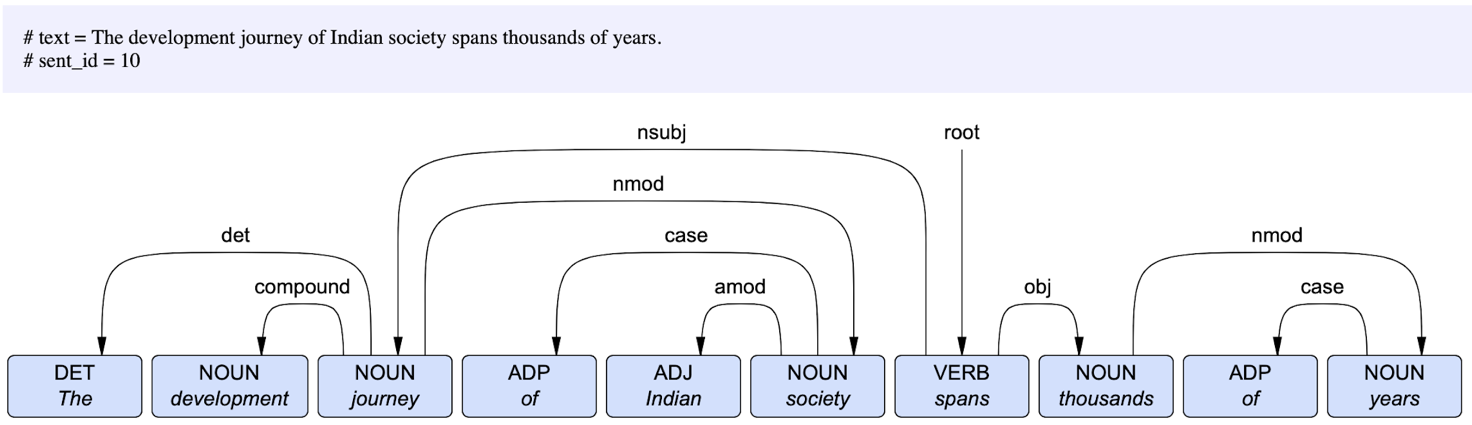
Syntax tree created by the author. The sentence was input into UDPipe, and the output was visualized with CoNLL-U Viewer.
Within the realm of dependency treebanks, the Universal Dependencies annotation scheme has established itself as a de facto standard. Universal Dependencies (Nivre et al. 2016) is a project aimed at developing a morphosyntactic annotation scheme that can be consistently applied across different languages. Version 2.13, released November 15, 2023, includes 259 treebanks of 148 different languages.
Parallel treebanks are a type of multilingual corpora that provide annotated sentence structures for two or more languages. The use of parallel treebanks offers several advantages for linguistic comparison, including the ability to directly compare the structures and features of different languages at the morphosyntactic level. This allows for more detailed and fine-grained analysis of linguistic phenomena across languages, such as word order variation or the use of particular constructions.
Due to the difficulty of finding translations of the same text that are freely accessible, parallel treebanks still constitute a rarity in the universe of annotated corpora in general (a notable exception is the PROIEL Treebank by Haug and Jøndal 2008, which contains the translations of the Gospels in the oldest Indo-European languages; cf. also the treebanks created during the shared task Parallel Universal Dependencies). This is particularly true for Indian languages, where parallel treebanks are scarce and usually involve only two languages, with English being one of them rather than a South Asian language (see a.o. Choudhary and Jha. 2014; Majumdar 2021).
At this point, the attentive reader will have gleaned that the forthcoming multilingual parallel treebank of speeches by Narendra Modi will be a collection of morphosyntactically annotated texts, both in the original Hindi version and translated into Marathi, Telugu, and English. All the speeches included in the corpus are sourced from the website of the Indian government (Menu > Media Library > PM’s speeches). As Modi’s speeches are translated and available in all the official languages of India, more languages will be added to the corpus as the project progresses and depending on the availability of annotators. Modi’s speeches are not the only parallel source of texts in the languages of India (see, e.g., Ramesh et al. 2022) but, unlike the Bible, they are contemporary, and, unlike legal texts and software localization, they contain somewhat more natural language. Thus, they allow for the study of trends in contemporary standard Hindi at various levels, together with their counterparts in the target languages.
Leading the project is a group of four researchers with diverse interests: Andrea Drocco, professor of Hindi language and literature, Sanskrit, and South Asian sociolinguistics, Lucrezia Carnesale, postdoctoral researcher in linguistics and Hindi expert, Luca Brigada Villa, doctoral student in linguistics, computational wizard, and enthusiast of typological linguistics, and myself, a historical linguist and Vedic scholar with a fondness for treebanks.
Given that with our expertise we would have been able to build nothing but a monolingual, non-parallel Hindi treebank, in January 2024, we organized a series of seminars on syntactic annotation open to all enthusiasts of South Asian languages. At the end of this recruitment campaign, eight native speakers and students of Hindi, Marathi, and Telugu joined our group, and the project was ready to begin!
To start our treebank, we performed automatic annotation using UDPipe, a trainable pipeline for tokenization, part-of-speech tagging, lemmatization, and dependency parsing. Trained models are available for all five languages in our parallel corpus in UDPipe. However, due to the lack of training data, the pipeline makes errors at all annotation levels, which we need to fix with manual annotation. Therefore, in the coming months, the annotators will be busy correcting the annotation generated by UDPipe; to do so, they will use CoNLL-U Editor, a tool which facilitates the editing of syntactic relations and morphological features of files in CoNLL-U format.
The annotation process will be lengthy, but we hope that the corpus will be a valuable resource for linguists and researchers interested in analyzing the linguistic and discourse features of Modi’s speeches, in the translation strategies used to translate them, as well as in South Asian contrastive linguistics.
If you want to know more and remain up to date on the progress of the Modi Treebank, visit the project website or stay tuned for future posts!
References
Abeillé, Anne (ed.). 2003. Treebanks: Building and using parsed corpora (Vol. 20). Berlin, Springer Science & Business Media.
Bader Markus and Häussler Jana 2010. Word order variation in the Germanic languages: A corpus-based comparative study. Lingua, Volume 120, Issue 3, 717-762.
Bonch-Osmolovskaya A. Nesterenko L. V. 2019. Multilingual parallel corpora as a source for quantitative cross- linguistic grammar research (the case of voice constructions), in Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue 2019”.
Choudhary, Narayan and Girish Nath Jha. 2014. Creating Multilingual Parallel Corpora in Indian Languages. In Human Language Technology Challenges for Computer Science and Linguistics: 5th Language and Technology Conference, LTC 2011, Poznań, Poland, November 25–27, 2011, Revised Selected Papers. Springer-Verlag, Berlin, Heidelberg, 527–537. https://doi.org/10.1007/978-3-319-08958-4_43
Haug, Dag T., & Marius Jøhndal 2008. Creating a parallel treebank of the old Indo-European Bible translations. In Proceedings of the second workshop on language technology for cultural heritage data (LaTeCH 2008) (pp. 27-34).
Lixun Wang. 2001. Exploring parallel concordancing in English and Chinese, Language Learning & Technology, Vol. 5, Num. 3, 174-184.
Majumdar Pritha, 2021. A Parallel Universal Dependency Treebank: English-Bengali and Hindi-Bengali, PhD Thesis.
Nivre, Joakim, et al. “Universal dependencies v1: A multilingual treebank collection.” Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16). 2016.
Ramesh, Gowtham et al. 2022. Samanantar: The Largest Publicly Available Parallel Corpora Collection for 11 Indic Languages. Transactions of the Association for Computational Linguistics, 10:145–162.
Yang, Guo-Ping & Chen, Yin. (2015). Investigating the English Proficiency of Learners: A Corpus-Based Study of Contrastive Discourse Markers in China. Open Journal of Modern Linguistics. 05. 281-290. 10.4236/ojml.2015.53025.

One thought on “A Parallel Treebank of Speeches by Narendra Modi, PM of India”