
Sometimes I miss watching movies with commercial interruptions, at the theater or on television. Not only were they a great way to refill your pop-corn bowl without missing anything. Advertisements are a cultural expression in themselves, and they can capture very well the historical moment in which they are produced. Some 15 years ago, when I still accessed movies by watching tv, an Italian brand of bottled water (I think it was Acqua Panna) designed a new bottle shape that, according to the ad, would fit better inside women’s purses, men’s handbags, and teenagers’ backpacks. The ad called it the “Prêt-à-porter” water, playing on the meaning of this term (“ready to wear,” to indicate a piece of clothing produced in standardized sizes, as opposed to tailored clothing), and creating a pun with the similar sounding and etymologically related Italian verb “portare” (“to carry with oneself”).
I realize now how telling the ad was about changes in our lives that soon would become ubiquitous. We now live in a prêt-à– world, where so much is easy to access and easy to carry, especially anything digital. Many things are increasingly becoming digital, like books. Readers of the Digital Orientalist well know how the digital world has made research “prêt-à-”: online cloud services, databases, and research tools allow us to retrieve data easily, sparing us from heavy bags filled with books; information management programs expedite the amount of knowledge that we can digest, saving us from putting pen to paper to scribble down notes and diagrams, which we could not search with a simple CMD+F in ten years’ time.
All good news? Yes and no. The critiques towards Digital Humanities and databases in general are renowned. My own history with the Digital Orientalist began because I wanted to promote some online tools that make working with ancient Chinese manuscripts more accessible, but whose usages and structures are also problematic. Here I want to continue to reflect on digital tools that make our work easier, perhaps too easy.
I want to discuss the database Guyin xiaojiing 古音小鏡 (Little Mirrors for Old Sounds). Its brief introduction indicates that the site started in 2017, and it aims to bring together materials and tools for the study of Historical Linguistics. This website, which is growing at an incredible pace, does much more than that. For example, in the menu options on the top right, there is a tab called “geographic names” diming 地名, under which there are four sections to explore geographic names in Mainland China, geographic names in the Wu languages and area (吳語地名 and 吳地地名 respectively), and names of localities used during the Northern Dynasties. A great advantage of this section is that you can use it even if you are working with partial information. E.g., if you know that there is a bei 北 in the name you are looking for, but do not recall or know much else, just use this value. The tool will do the rest, and pull out a list of geographical names that include bei.
But the website is perhaps better known, at least among scholars of ancient China, for its section on Old Chinese reconstructions, which was recently expanded. Just navigate to “Reconstructions according to 16 systems” 擬音16家 under the “Tools” 工具書 section on the top right, to be prompted to a search box under the heading “Old Chinese, Middle Chinese.” Search any word in it, and it will lead you to two tables, one for Old Chinese and one for Middle Chinese. The image below shows how they are organized.

An important feature of this database is that it disambiguates which word a character is writing. Pronunciation is a feature of the word, not of the character –a fact that appears often underestimated in the scholarship. Take the example of “to grow; elder” and “long”. They are both written with the graph 長, but each word had its own specific phonological features:
“to grow” zhang < trjangX < *traŋʔ
“long” chang < drjang < *Cə-[N]-traŋ
And precisely, Little Mirror disambiguates 長 accordingly:
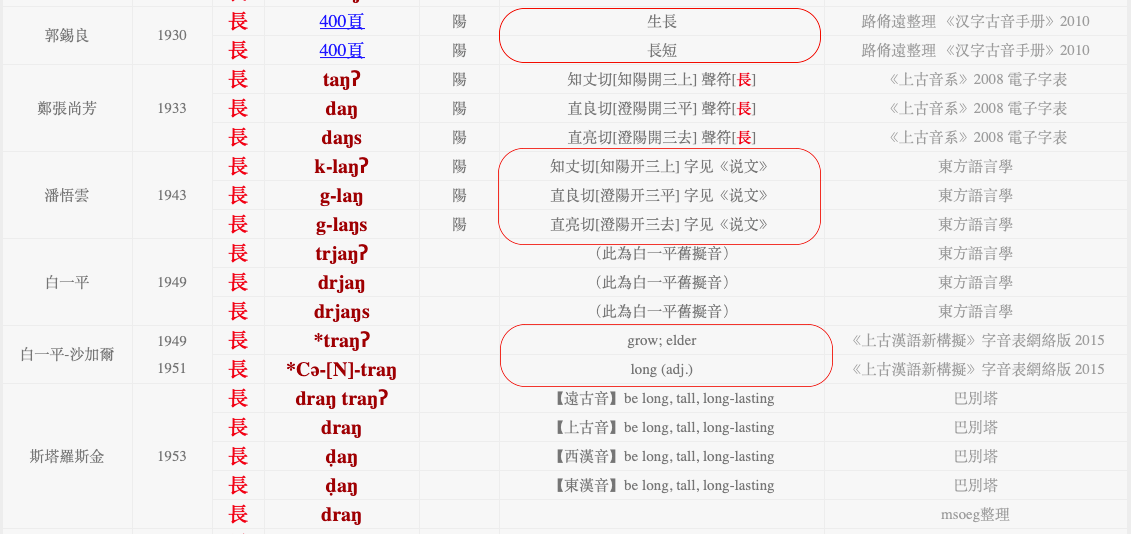
Old Chinese reconstructions, prêt-à-porter. And “prêt-à-reproduce”: the data can be copied and pasted. This can be pretty handy. As I have introduced in my first article, a feature of Chinese language is that of “phonetic loans” 假借, i.e. the possibility of writing a word by using the graphic representation of another word, provided that the two words are homophonous. (Almost the reverse of the phenomenon just illustrated above.) A famous example is that of the words “to come” and “wheat”: since they were pronounced *m-rˤək in early stages of the language, “to come” was written with the pictogram of “wheat”  . Ancient manuscripts are filled with phonetic loans, and thus scholars are always keeping an eye on Old Chinese reconstructions in their research to spot these cases and understand exactly which words each character may be writing. You can imagine how a tool such as the Guyin can impact someone’s research.
. Ancient manuscripts are filled with phonetic loans, and thus scholars are always keeping an eye on Old Chinese reconstructions in their research to spot these cases and understand exactly which words each character may be writing. You can imagine how a tool such as the Guyin can impact someone’s research.
A happy ending for scholars of early China? Not quite. There are small and big problems with this database, in particular with its usages. A small, and yet an important one: in the table for Middle Chinese, the data pulled from William Baxter and Laurent Sagart’s Old Chinese is presented as a reconstruction (擬音), when in fact the authors insist that what they devised is a transcription of Middle Chinese.1 We could spend weeks discussing the ontological differences between “reconstruction” and “transcription,” and some linguists would tell you that what Baxter proposes is in fact a reconstruction. Here the point is that a database that presents itself as a tool for the study of Historical Linguistics should signal this.
A bigger problem lies in the usage of its data, since it can be copied without having to understand how the reconstructions are obtained. Uncritical replication leads to all sorts of methodological flaws. To begin with, they may contain errors. This database rightly warns about it, and invites users to rely on original sources (注意:電子材料常有疏失、錯誤,準確引用請一定要核查學者原書). As my colleague Mariana Zorkina mentioned in a recent article, blind reliance on results produced by someone else undermines, rather than improves, research. Of course, we are all experts in our chosen field, and as such our scholarly products should be trusted. But we are also humans, and, more importantly, new data that may disprove previous hypotheses are continuously introduced in the field.2
Furthermore, none of these reconstruction systems provide reconstructions for all known words in Old Chinese language – how could they? The aim of a system is exactly that: providing a framework that allows researchers to reconstruct the necessary phonological values. This is not what happens. When a reconstruction system does not include the word one is looking for, a solution has been that of jumping to the next reconstruction system that includes it.3 Mix-and-match however is good for COVID boosters. It is not a valid method when working with Old Chinese reconstruction systems –or any reconstruction system, for that matter.
The importance of a tool like Little Mirror ought not to be underestimated. This database is a gold-mine for data comparisons, and much more. But at the end of the day, databases collect signals. And signals are meaningless outside the interpretative systems from which they derive. The good news is the wide availability of resources, including digital ones, to expose oneself to absorb the principles of linguistics, phonology, and reconstruction systems, so as to increase knowledge, rather than replicate it.
_____
Footnotes
[1] William Baxter, A Handbook of Old Chinese Phonology, Mouton DeGruyter, pages 27-32.
[2] Just yesterday Dr. Guillaume Jacques remarked the importance of being acquainted with phonology and how reconstructions work in a talk delivered for the project Methods in Sinology.
[3] E.g., Jonathan Smith’s 2018 SHUN 舜 AND THE INTERPRETATION OF EARLY ORTHOGRAPHICAL VARIATION. Early China, 41, 415-422; and in Documentation and Argument in early China by Dirk Meyer, with a notable case in chapter one footnote 27 that brings together all that I have highlighted in this article. The author states that the graphs 閔 and 暋 are unproblematic phonetically, but as mentioned, the phonological value is that of the word, not the graph. The two are assigned reconstructions according to different systems: Baxter and Sagart for 閔 (the system the author says to be following, page 38). When it comes to 暋, which Baxter and Sagart do not reconstruct, we find a value from Zhengzhang Shangfang’s 鄭張尚芳 study Shangguyinxi 上古音系–or so I assume, since there is no explicit indication. Curiously, the reconstruction for 暋 is also not preceded by the asterisk that signals reconstructions of phonetic values.
One thought on “Old Chinese Prêt-à-porter. A double-edged sword. ”