
Guest piece by Casey Schoenberger.
The following is an introduction to a digital humanities project I completed over the past three years as part of my research on musical and linguistic aspects of traditional Chinese poetry and vocal art. Many thanks to The Digital Orientalist for this opportunity to share my work.
Created with support from the Hong Kong University Grants Committee (UGC) and assistance of freelance programmer Austin Chen, research assistant Jiang Qixin, and two student assistants, the Nine Modes Manual Online is a digitization of one of the oldest, largest collections of traditional Chinese vocal melodies in existence, the Jiugong dacheng nanbeici gongpu 九宮大成南北詞宮譜 (Nine Modes Comprehensive Northern and Southern Lyric Melody Manual). The database is hosted at the Hong Kong Polytechnic Pao Yue-kong University Learning Hub, and the landing page may be found at https://dc.lib.polyu.edu.hk/ninemodes/intro.html. The directions and interface are available in both English and Chinese, though full use of the database presumes a degree of Chinese reading ability, as it was not practical to translate every tune title (qupai 曲牌) or searchable lyric in the whole collection of over 6,000 pieces.
The motivation to create this resource was my research on music and language interactions in traditional Chinese poetry and drama, which led me to study Kunqu 崑曲 (Kun opera), the oldest operatic singing tradition still practiced in China. As one of the earliest and by far the most comprehensive premodern records of Kun opera melodies, the Manual is an unparalleled resource for the study of this art and associated literary works, which include many of the most popular plays and art songs of the sixteenth through eighteenth centuries. The problem was that it only existed in hard copy and unsearchable PDF scans of a rare book edition, part of Wang Qiugui 王秋桂 et al.’s Shanben xiqu congkan 善本戲曲叢刊(Collectanea of Rare Theater Texts) series.
Even with the helpful table of contents included in that edition, simply locating a particular piece or set of pieces within the massive collection was time-consuming, to say nothing of analyzing finer details. It was further clear to me that the vast information contained in all the musical and prosodic details of the collection was a prime target for a digital approach, as there was surely statistical data to be gleaned beyond the capabilities of any individual to clearly recognize. The first goal of this project, therefore, was to make the whole collection searchable. This in itself was a major undertaking made possible by the efforts of Austin Chen to create a text recognition system specific to the collection, thereby giving a rough approximation of the melodies, and of my research and student assistants, who completed the time-consuming work of error-checking this rough output.
Beyond this, I worked closely with Austin to create a variety of tools for analyzing musical and prosodic parameters of the pieces and their interactions. These provided quantitative data about such questions as the most frequent line lengths in the whole collection, the most common rhythmic qualities of lines of a particular length, the special characteristics of pieces belonging to different regional categories, and much more. This helped me prove important conclusions about Kun opera singing for my upcoming book, The Voice Extended: Music, Mind, and Language in Chinese Poetry and Performance, and I hope they may be of use to other scholars interested in such analysis.
How to use the Nine Modes Database:
The two primary ways a user may approach the collection are “Query Engine” and “Full-text Browsing”:

Between the two, “Query Engine” is especially suited to searching for particular information, like the locations of pieces of a given title within the collection, the number of beats per syllable within a subset of pieces, the associations between tonal and melodic patterns, and so on. “Full-text Browsing,” by contrast, provides a simpler interface of pull-down menus, allowing a quick overview of mode-key (traditional musical category), source (including names of particular dramas), and piece names. This makes it better for general browsing:
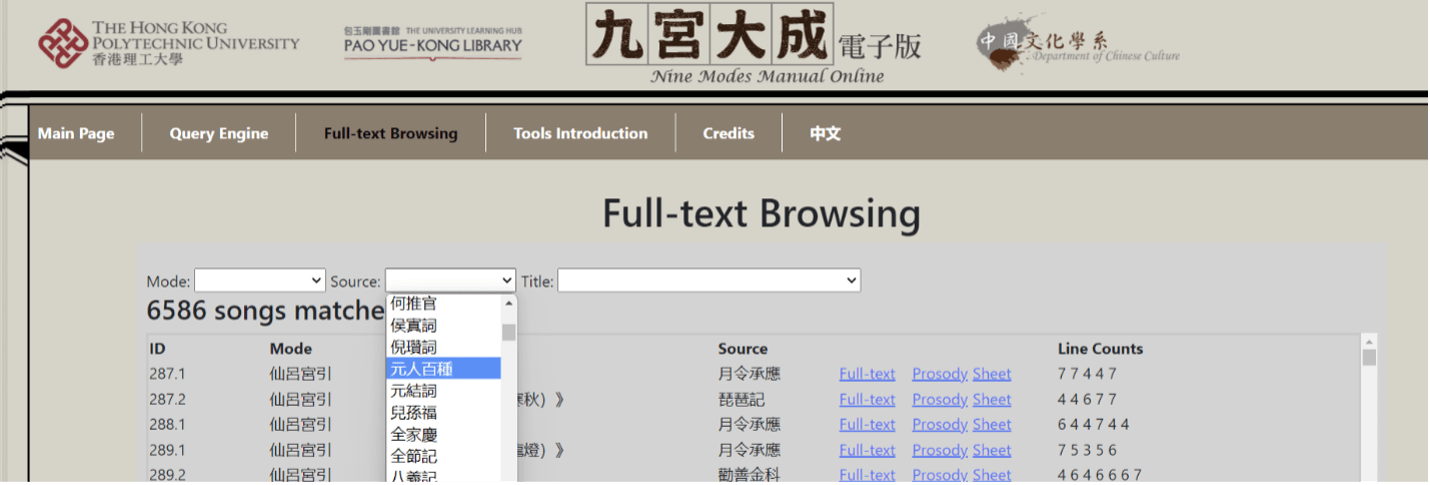
The source “元人百種,” for example, refers to pieces within the collection drawn from Yuan Dynasty zaju 雜劇 (“variety drama”). Some sources include a poet’s name plus the word ci 詞 (“lyric”), such as Ni Zan ci 倪瓚詞 (“a lyric by Ni Zan”), and some sources are the names of chuanqi 傳奇 (“marvelous tales”) dramas, popular in the late-Ming and early-Qing Dynasties especially, such as Bayi ji 八義記 (Eight Righteous Ones).
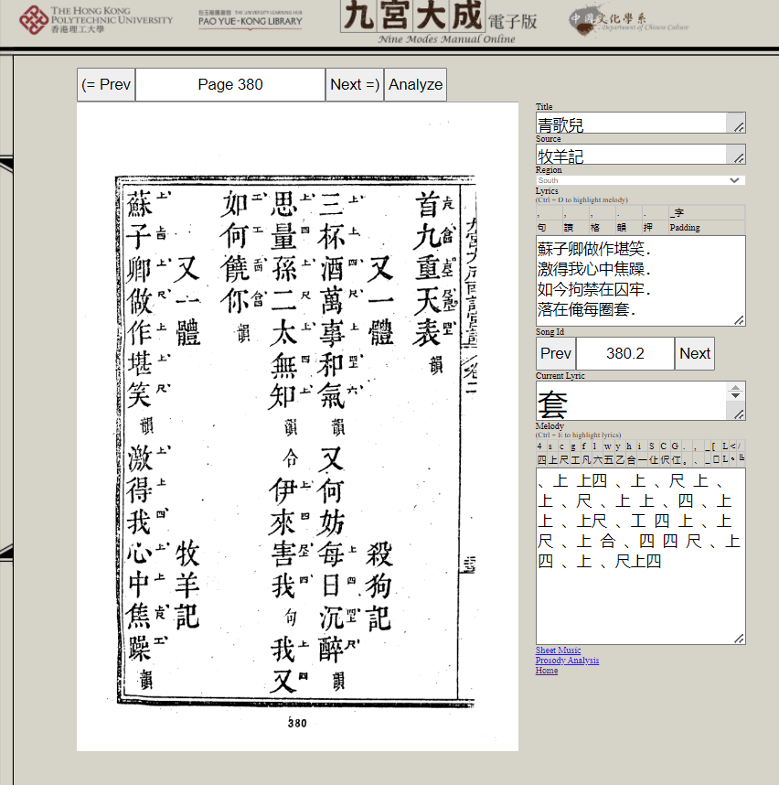
Clicking “Full-text” will allow you to view a scan of the original print copy of the collection, clicking “Prosody” will allow you to view a comparison of prosodic features of different pieces of the same title, and clicking “Sheet” will auto-generate a stave notation of the piece in question. To the right of these options are a series of numbers indicating the total number of characters per line in the piece. That is, piece 287.1 consists of five lines of seven, seven, four, four, and seven syllables.
The following is an example of “full-text,” showing how the original notations look on the page:
The “Prosody” feature generates a page like this, with each character in a piece occupying a box that includes more or less musical and prosodic information associated with those characters as selected by the user:
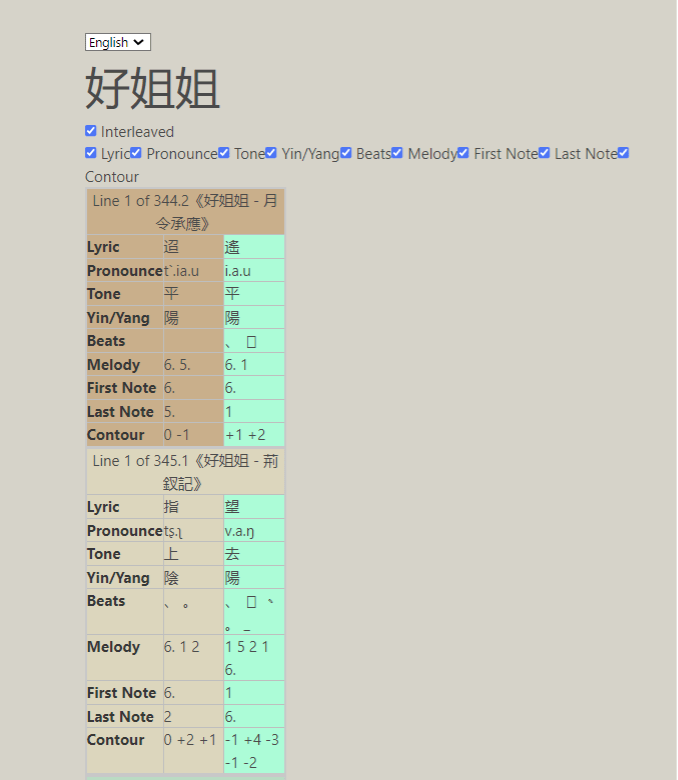
Above are the first lines (only two-characters long) of two version of the title Hao jiejie 好姐姐 (Good Sister). Ticking “interleaved” will display the first line of every piece of a particular title, followed by the second line of every piece of that title, and so on, whereas unticking “interleaved” will display each piece in full before displaying the next piece of the same title. This feature allows users to compare and contrast different versions of pieces of the same title, such as whether certain line positions usually use a character of a particular tone or associate with a particular melodic motif. Because of the high variability among different pieces associated with the same traditional tune title, this feature may help users disentangle any “core” elements of a title from more flexible, incidental, or idiosyncratic elements.
Below is an example of the auto-generated sheet music stave notation, which includes an option to play a midi of the melody. Although these are not polished arrangements and required adopting certain basic assumptions about rhythmic ambiguities inherent in the collection, reading or listening to such outputs may help scholars gain a basic sense of what a particular melody might have sounded like in the eighteenth century. Included are IPA renderings of Kun opera pronunciation from a specialized dictionary. The dots between parts of syllables indicate how enunciation of the syllable may be broken up in performance:

The Query Engine relies primarily on two search bars to allow users to pinpoint features of particular pieces, groups of pieces, and/or lines, with the upper search bar being used to filter pieces and the lower search bar for lines:
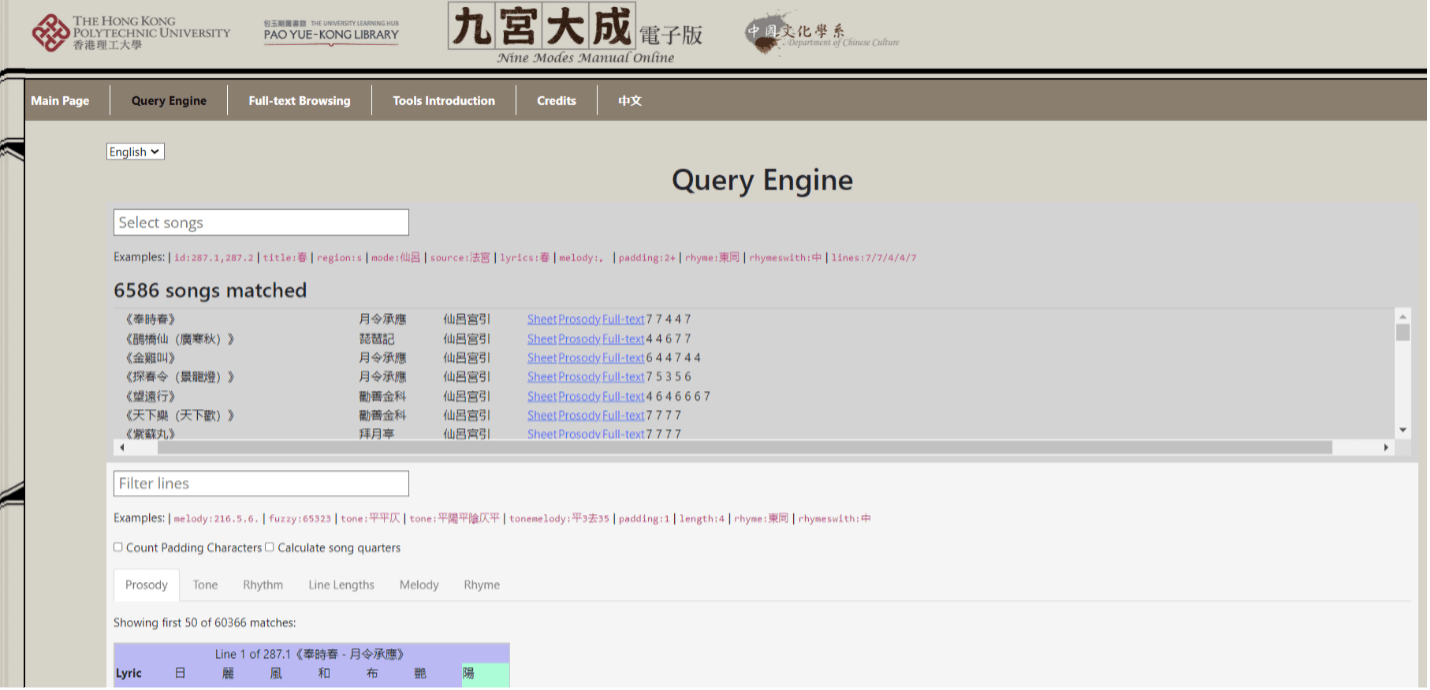
For example, if one wishes to search for all the pieces in the collection from the play Mudan ting 牡丹亭 (Peony Pavilion), one enters: “source:牡丹亭” (without quotation marks) in the upper bar (play titles are considered “sources,” as are author names; the collection does not list authors of plays, however, only individual lyrics). If one wishes to find all the pieces the aria title of which includes the phrase feng ru song 風入松 (Wind through the Pines), one enters: “title:風入松” in the upper bar. If one wishes to find all the pieces with the phrase chunhua 春花 (“spring flowers”) in the lyrics, one enters: “lyrics:春花,” and so on.
The bottom search bar is used to narrow a search to lines with specific qualities, such as those of a certain length, those that use a particular tonal pattern, or those that include a particular series of notes in a row. For example, if one wishes to find all the lines in the collection that include the melodic phrase “do, re, mi, re, do,” one enters: “melody: 12321” in the bottom bar (1=do, 2=re, 3=mi, and so on). “Fuzzy” allows a search for an imperfect melodic match, as may be helpful for finding motifs that are repeated, but not exactly. The “find motifs” button further automatically identifies repeating melodic patterns within whatever portion of the collection is currently selected, sparing the researcher the work of knowing in advance which motifs to look for. I recommend first narrowing the collection by filtering the pieces and/or lines before using the “find motifs” function, as otherwise the search may stall or produce more results than the system can currently display.
Both search bars allow multiple queries, and the two bars may be used simultaneously. For example, if one wishes to find all the pieces belonging to the Northern regional style in Peony Pavilion, one may enter: “region:n source:牡丹亭” in the upper bar. If one wishes to find all the lines using four “padding characters” (chenzi 襯字) in Peony Pavilion, one many enter: “source:牡丹亭” in the upper bar and “padding:4” in the lower bar.
Below the lower bar is a series of tabs used for analyzing aspects of selected pieces and lines, such as their rhythm and melody. Ticking “calculate song quarters” is necessary for analyzing rhythmic qualities of pieces, and “count padding characters” determines whether padding characters are counted in determining the lengths of lines. In the example below, I have first narrowed the collection down to only Northern style pieces by typing “region:n” in the upper bar, and further narrowed analysis to the lines of four characters in Northern pieces by typing “length:4” in the lower bar. I ticked “calculate song quarters” and selected the rhythm tab to help me figure out how often particular rhythmic markers appear associated with particular line positions within the selected subset of pieces and lines. I copy-pasted one of the rhythmic markers (in this cases a 、corresponding with something like a downbeat in traditional notation; see “Tools Introduction” for more details), and the system generated a bar graph indicating the frequency with which this marker appears in certain positions. In this case, for example, we can learn that a downbeat is highly unlikely to correspond with the second character of a four-syllable line in the Northern style:

The above is only a brief introduction to all this system is capable of, and I am confident that other scholars could easily notice patterns and draw conclusions that I have overlooked if they take the time to explore it. Giving tremendous credit to my collaborators and taking full responsibility for any errors or bugs that may remain, I hope this still comparatively small example of what may be possible using digital approaches inspires further work in this area.