
This is the second part of an interview with Arezou Azad, Senior Research Fellow at Oxford University’s Faculty of Asian and Middle Eastern Studies. Dr Azad leads the Invisible East programme at Oxford. You can read part one here.
Q5. Theodora Zampaki: What are your core goals?
Dr Arezou Azad: Our research goals are broadly threefold:
a) To understand the roles played by different stakeholders (political, religious, legal, financial) in the construction of multicultural communities and societies across the Islamicate East;
b) To ascertain how texts and material culture help us understand relations between Muslims, Jews, Buddhists, Zoroastrians, Christians, and other faiths in the Islamicate East; and
c) To establish how the Persian language developed and interacted with other languages (Arabic, Hebrew, and others) in the multicultural Islamicate East.
I also feel strongly about sharing our findings with as wide an audience as possible (in fact, our British funders demand this sort of “impact” work from their grantees). We aim for the documents we process to be made available to the public through the IE digital corpus. We also run various outreach activities, such as, taster sessions in schools around the UK.
At the schools, we carry out three interactive exercises with 11 to 14-year olds to discuss topics related to our programme, such as, medieval society in the eastern Islamicate world, and the ethics of working with primary (and unprovenanced) sources that are in the public domain. Our teaching materials are available on our website for anyone who would like to replicate or adjust the course for their own needs. We are now extending this type of engagement to schools in the region from which the documents come. We are also hosting various public Webinars and have already reached several thousand people from non-academic audiences in this way.
Q6. What research tools have you developed?
We have developed a variety of research tools, many of which are available for free to download on our website (https://invisibleeast.web.ox.ac.uk/resources). The tools include:
- Inventories of documents in each of our seven languages with detailed meta-data and tags
- A Storymap of each of the documents we work on.
- Our digital corpus is still in process; the backend codes will be made publicly available once they are finalised so other scholars can use or build on them
- Bibliographies of secondary literature on our documents
- Palaeography guide to reading the New Persian documents which contain some of the earliest surviving writing in Persian
- Document management sheets (DMS)
- A digital timeline of the earliest New Persian writing that hits home the story of Persian in a way that hasn’t been told before: one that is based on original sources.
Our digital timeline of Persian was prepared principally by Pejman Firoozbakhsh, and is quite revolutionary because it shows the timeline of Persian texts based on available originals (rather than much later copies of texts). It changes the way we use sources when looking at language development and writing. The famous Persian epic, Shahnameh, for example, which is often called the first piece of Persian writing, in fact only survives in much later copies. The earliest original Persian writing, rather, are some Persian notes on Qurʾānic booklets, then come the earliest documents from Afghanistan.
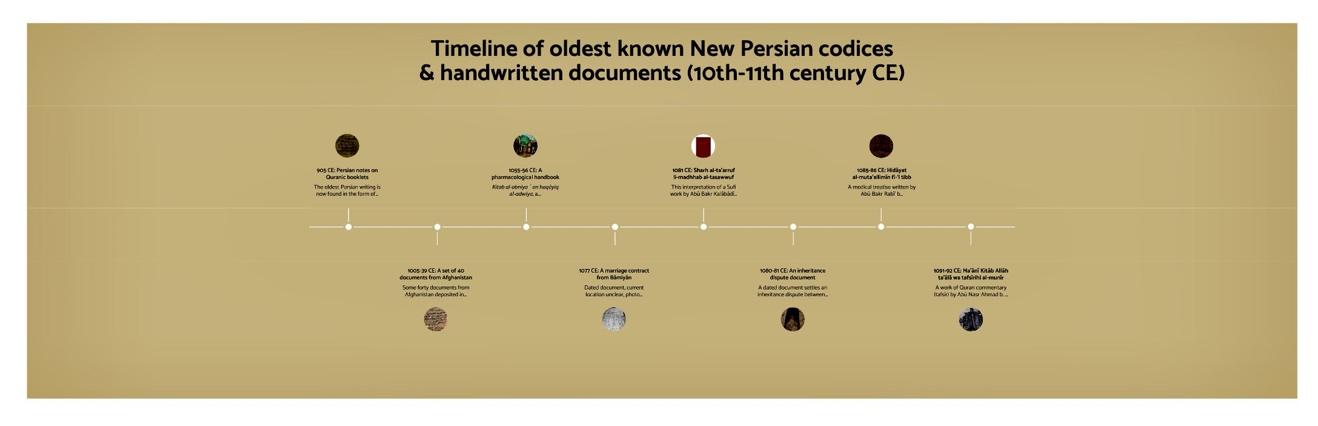
The timeline software we use is dynamic and easy to navigate: users can scroll along it, and by double clicking on a source, obtain further glosses and information like this:

Q7. In what way can the research tools be used by a scholar working on Graeco-Arabic Studies?
A scholar working in Graeco-Arabic Studies, or any other language, and studying documents could find our tools useful as an example, or possibly even a template to follow, for making their own inventories, Storymaps, timelines, corpuses, or document management sheets. All these tools can help researchers working in any philological enterprise bring order to the documentary evidence base that is spread out across different and often inaccessible publications across the globe. They will enable scholars to process, synthesize, and visualize these dispersed data in a meaningful way, and to make such data inter-searchable with data in other corpuses using XML-TEI related technologies.
Q8. How does the inventory of Arabic documents from Central Asia and Iran work?
The inventory is on our website and was prepared by Tommy Benfey. It is divided up by depository. In this case, we have the Oriental Institute of the Russian Academy of Science, the National Library of Israel, and the Nasser D. Khalili Collection. A fourth set is based on the publication by Monika Gronke of Arabic Documents from Yarkand (also included in the Arabic Papyrology Database). Each sub-inventory includes: the official catalogue number, the type of document (e.g., legal, administrative/state, or literary), a brief content summary, place of origin, a date if it is dated, and writing surface. Thus, anyone interested in getting a quick birds’ eye view of the surviving Arabic documents can get it here, and nowhere else. We also give a bibliography for anyone interested to find the full document texts. Once our digital corpus goes online this will be only a click away.

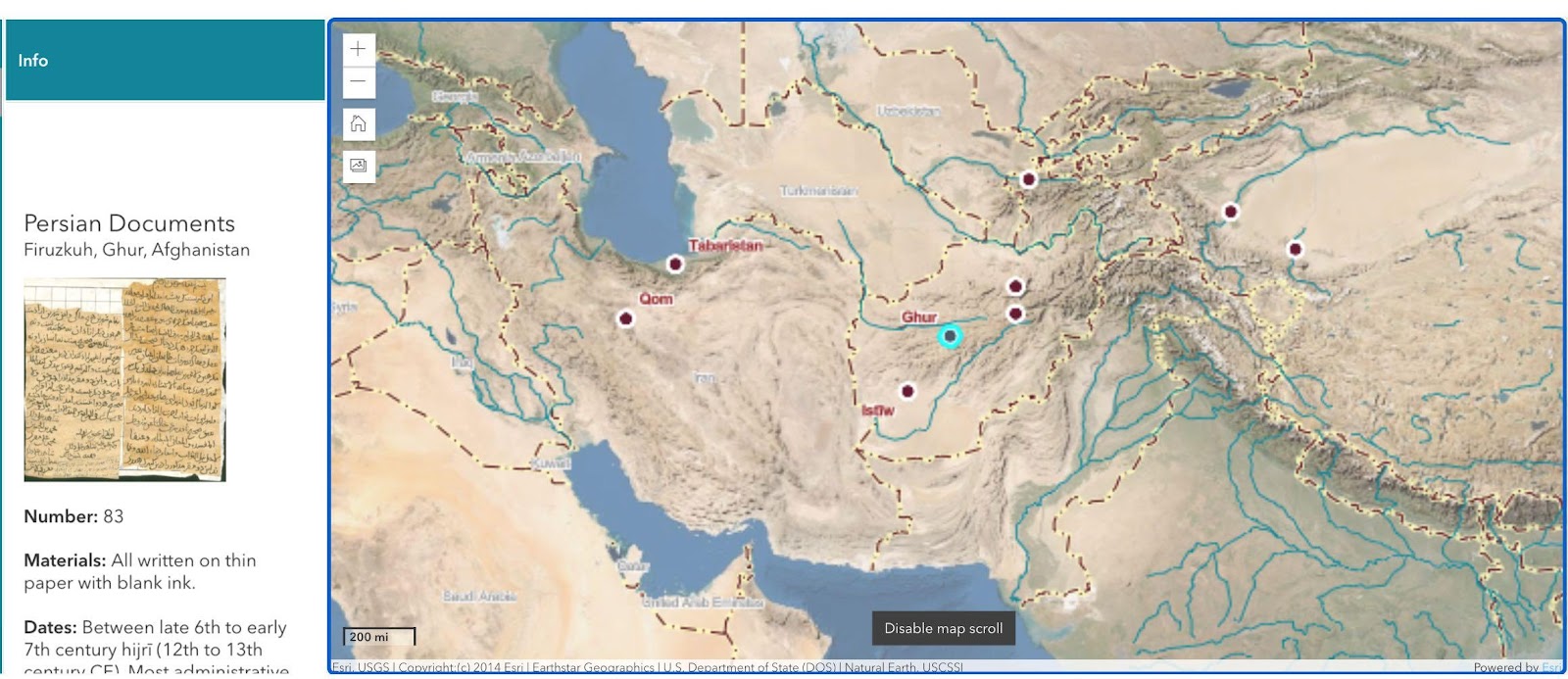
Q9. Can you present the Storymap of the Islamicate East?
The Storymap was produced by Michael Athanson on our behalf. Mike has extensive experience as the former head of Oxford’s Bodleian Library’s map room. He received the coordinates for the sites of our documents (some are only approximate given the unfortunate lack of provenance). The coordinate markers are overlain on Earthstar Geographics (TerraColor NextGen) imagery with a resolution of pixels in the source image covering a ground distance of 15 meters with an accuracy of objects displayed in this image within 12 meters of true location. These are then linked to fact sheets each researcher prepared on each document linked to that location. Some fact sheets cover multiple languages, and the researcher will need to scroll down the sheet to get to the next language(s). It is a visualisation tool that helps in understanding the ecology and topography of the region from which the documents stem: this is particularly important given that the majority of the documents deal with issues of land and water management, transportation, and similar issues. The Storymap also helps scholars in estimating the distances between the different document corpuses, and possible transmission routes across these locations.
One thought on “Interview with Arezou Azad on the Invisible East Programme and its Digitisation of Documents from the Medieval Islamicate East, part 2”