
Representing Arabic script on a computer has been problematic from the very beginning. In this series, we shall explore some of the solutions offered. First, we need to understand what is so problematic about Arabic script in a digital world.
Arabic was developed a millennium and a half ago, and found its first expression through rock inscription and pen and ink. Pen and ink became the de facto mode of expression and the Arabic script developed in this medium. Most of the more technical aspects of Arabic script were developed as a response to a need to record the Koran as precisely as possible, e.g. elongations, assimilations, points at which to stop and at which to keep reciting.
Printing Arabic
Fast forward to the printing era. Lithography went along well with Arabic script because its technology was based on the principle on preparing an entire page as though a stamp, and then stamping it on as many pieces of paper as one wished. But printing became much more popular using the technology called movable type. This technology constructed a page not as one stamp, but as hundreds or thousands of tiny stamps, arranged in rows, each stamp representing one letter or reading sign. It is called movable because you can move around each stamp, and reuse the stamps for every page instead of having one unique stamp for each page.

Latin script lends itself quite easily to this type of printing. Movable type for Arabic was developed similarly, on a per letter basis. Arabic, however, is not written on a per letter basis, but on a per letter block basis. For example, the word المعروف is written not with five letters but with four letter blocks, the first is ا, the second is لمعر, the third is و, and the fourth is ف. Especially the second letter block knows special ligatures, with the lām on top of the mīm, and the mīm presented as a tick to the right.
Take this zoomed in excerpt from an early print from Brill Publishers, circa 1890:

We see that each letter has its own stamp. Notably, Brill actually accommodated the normal ligature for mīm and ḥa, as one stamp. Nevertheless, the approach taken here makes it very inflexible. Moreover, the open spaces provide for an uneven reading experience, in which it is sometimes hard to distinguish where a word ends. The latter problem has been solved; we do not see the spaces in between the letters in more recent printed works. The inflexibility persisted and has arguably only become more aggravated in the 20th century with most publishers using less ligatures.
Arabic on computers
In short, as we will discuss throughout this series of posts, these flaws of movable type transferred to the digital representation of Arabic. One way to look at the persistence of this problem is that these technologies, printing press and computers, were developed in Latin script based societies and thus took that use case as a matter of fact. The rest of the world, with its many varying complicated scripts, had to bend to these rules. It seems that even though Arabic is the sixth language of the world, there was little economic incentive to fundamentally solve these issues.
In fact, the digital environment aggravated the problem even further. Taking the movable type philosophy of dividing text into letters, computers have had a significant problem in representing Arabic as connected letters. Take the following example:

Some poor soul decided to translate “what doesn’t kill you makes you stronger” into Arabic, type it out on a computer, print it and give it to a tattoo artist to have it as a tattoo. Where letters should have been connected to look like ما لا يقتلك يجعلك أقوى, all letters are represented individually. In a horribly simple typeface as well, I might add. (this is Arabic tattoos done right)
Further, computers have had a terribly hard time figuring out that some cultures write from right to left instead of left to right. Thus, when typing, the letters could turn out in the exact opposite order. Here is an example from Baltimore-Washington Airport:
Or this:
Lastly, computers have seemingly trouble with encoding Arabic. Encoding means that the visible representation on the screen has a string of 0s and 1s that a computer can actually store, that this string is stable so that a visible representation can be taken and repurposed somewhere else and indeed be the same. Examples will make this clear.

In the image above, we can see that if we select the word hādhihi, copy it, and then paste it into the search function, we get a completely different string of characters.
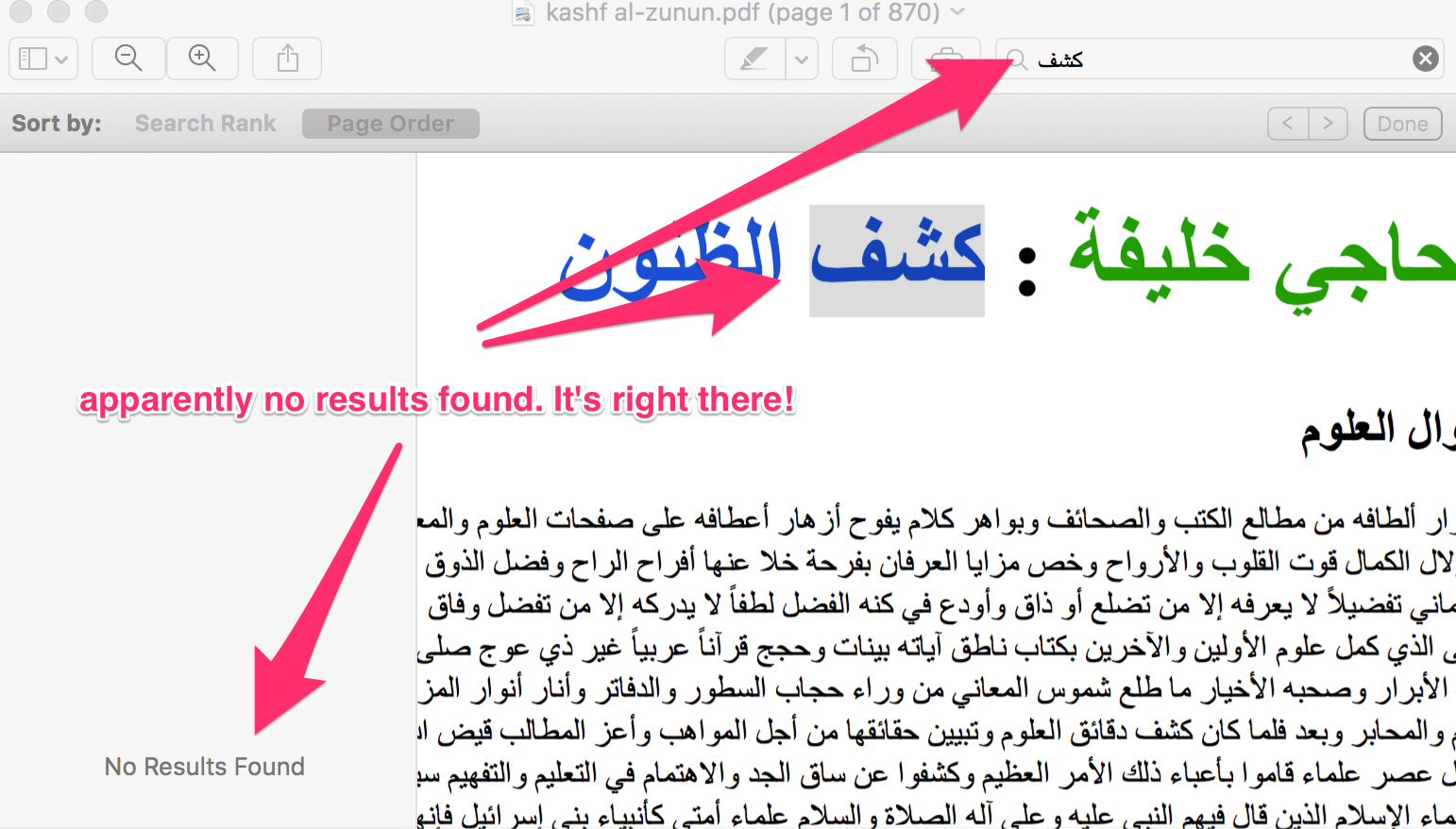
In the image above, we typed كشف in the search bar, and even though the third word of the document is exactly كشف, the PDF viewer cannot find anything of the like.
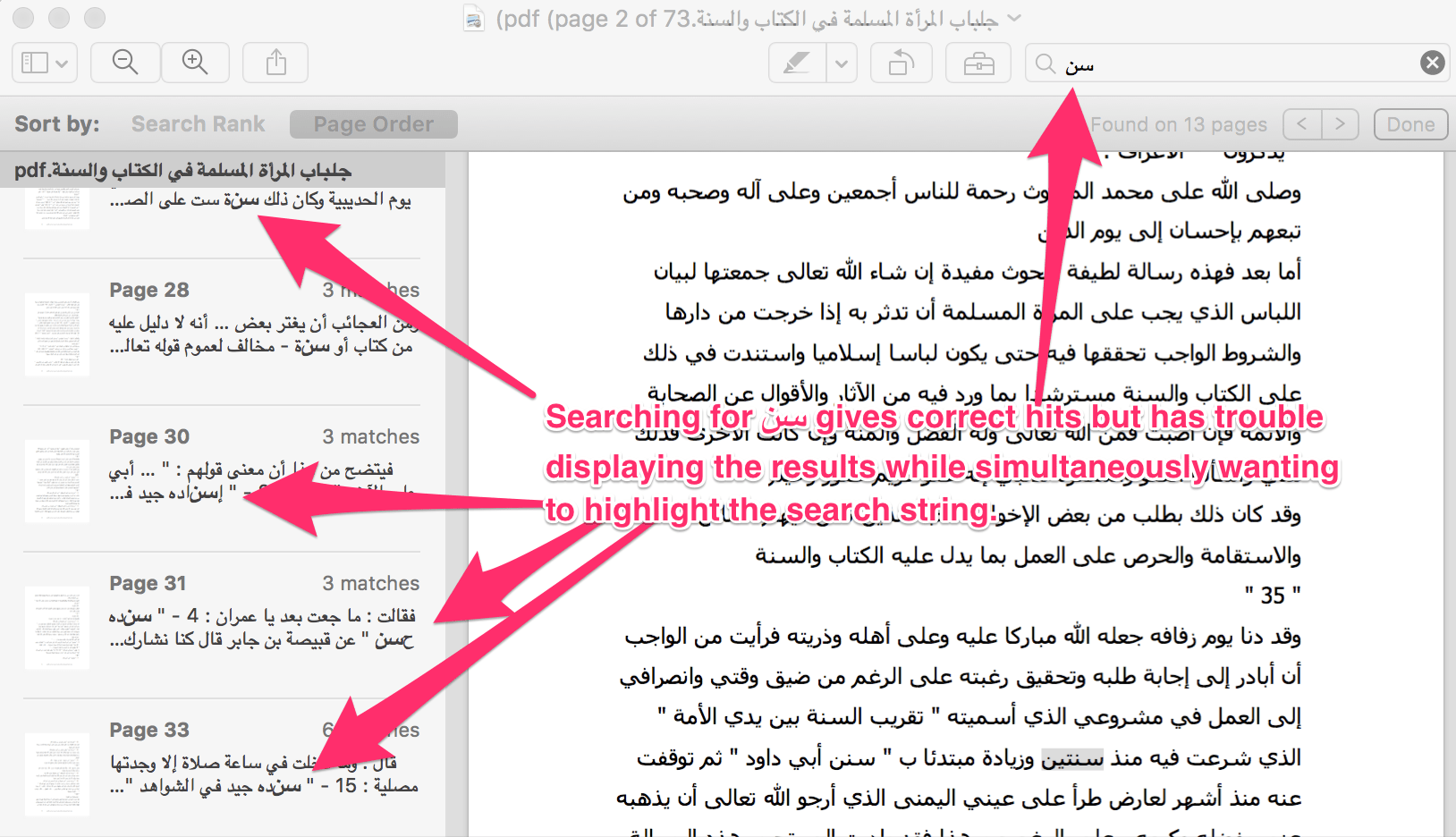
In the image above, most things go right. We search for سن and get everything from the instances of the word sinn to sunna, to ḥasan, to isnād. In the search results, however, the PDF viewer wants to highlight the search string by making it bold. This breaks the connection with the previous and following letters, making for an awkward view. Working with Arabic invariably makes you come in contact with these problems at some point.
Unicode
Solutions to such problems have been proposed, but not widely or accurately implemented. Some problems were proposed to be solved with what is called unicode. This has become the standard for digital text, much like what movable type did for printing.
Unicode is is simply a table which all companies agree to use, in which every character of every language is assigned a unique number. This means that the digital text file is a series of these numbers, which every computer can render into readable characters as they wish. For example, different fonts give different shapes to the same letter. So, the font can be changed without any changes occurring to the digital text. In other words, abstract letter and actual representation are separated. Unicode calls this difference a difference between characters and glyphs. The most notable example is that the characters for Chinese, Japanese, and Korean (CJK) have been unified. Only by showing the text in a font designed for Chinese will the text look like a Chinese text.
A similar approach could have been implemented for Arabic too, for example by distinguishing rasm from diacritics and vocalization. This would not only solve problems from the printing era, but go over and beyond it by providing an ultra flexible approach to the Arabic script, one that does more justice to the writing practice and hence its philosophy. Instead, Unicode has encoded Arabic letters separatedly. Rather than considering a ta marbūṭa as a ha with two dots, it sees it as a separate letter. Searching for كثيره and كثيرة will in most cases yield different results, even though that it arguably should not do that. A similar issue occurs with vocalization and other super or sub signs. One can type أ, which is alif+hamza, with unicode number U+0623, but one can also type أ, which is an alif and a high hamza, represented by unicode numbers U+0627 and U+0654. Clearly, they are the same. They are both alif-hamza. But because they are encoded in different ways, they are usually not picked up as identical by computers. (In most cases, texts are written with the alif+hamza character.) Not even the simple idea of CJK has been implemented. What I mean is that a kāf should be a kāf, encoded as one and the same letter, but which may find different graphical expressions in different variants of writing, such as Arabic and Persian. But no, we find an entry for an “Arabic kāf” https://codepoints.net/U+0643, and an entry for a “Persian kāf” https://codepoints.net/U+06A9 (the latter incidentally still called ‘Arabic’).
More problems than solutions
And so, print introduced problems to representing Arabic, especially because of movable type, and computers introduced more problems, notably because of Unicode. We live, then, in a world in which we have to fight for correct Arabic. And most of us are not willing to stand up for it. The end result is that our abilities for Arabic on the computer are severely limited. Not only can we present it on a screen and print it on paper in only a rudimentary fashion, we often encode it such that it is not flexibly searchable and therefore has limited repurposing possibilities. Stay tuned for more.
2 thoughts on “Digital Printing of Arabic: explaining the problem”